
Deployment容器编排?怎么编排
工作负载
在上一章中, 我们简要的了解了工作负载的作用及其概要, 在这章节的学习中 , 在学期容器编排之前 , 让我们来再加深一下对工作负载的理解。
在Kubernetes中,工作负载是对一组Pod的抽象模型,用于描述业务的运行载体。这些工作负载类型帮助用户定义和管理他们的应用程序,确保它们在容器化环境中高效运行。
借用我阅读的过的文章的一个图, 来表示一下工作负载到底再干什么?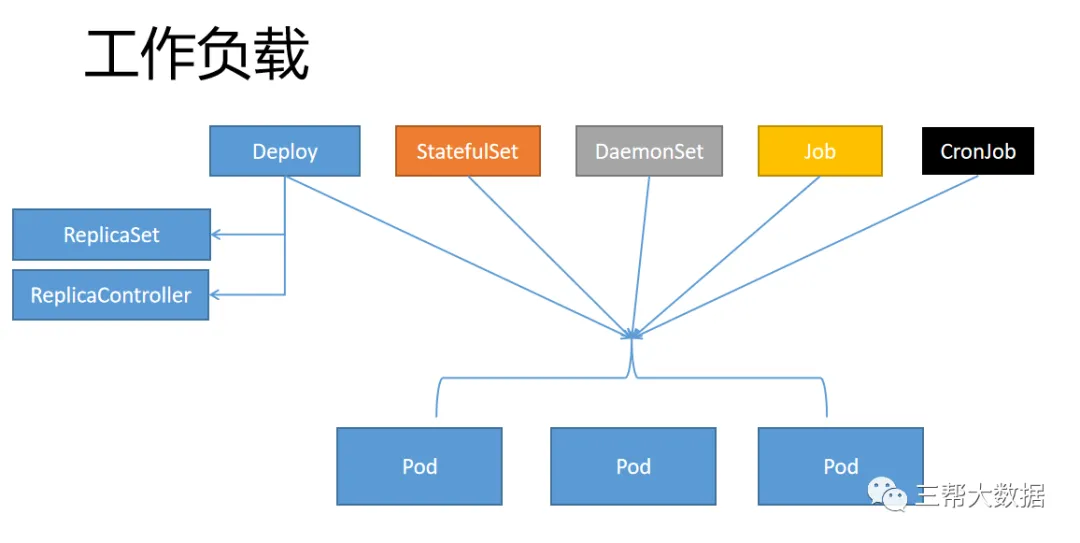
从图中清晰明了的看到,工作负载管理者一组pod ,而pod其实是一组或者一个容器的集合。 所以说, 工作负载是一组pod的抽象模型。
Deployment是一种工作负载,在Kubernetes中用于描述期望的状态。具体来说,Deployment是用于部署、扩展和管理Pod的API对象,它代表用户期望的Pod集合的状态。
为什么要有工作负载?
为了减轻用户的使用负担,通常不需要用户直接管理每个 Pod。 而是使用负载资源来替用户管理一组 Pod。 这些负载资源通过配置 控制器 来确保正确类型的、处于运行状态的 Pod 个数是正确的,与用户所指定的状态相一致。这就是我前面所说的工作负载代表用户期望pod的状态.
在张磊老师的深入剖析kubernetes中,他是这样描述deployment的。
Pod 这个看似复杂的 API 对象,实际上就是对容器的进一步抽象和封装而已。
说得更形象些,“容器”镜像虽然好用,但是容器这样一个“沙盒”的概念,对于描述应用来说,还是太过简单了。这就好比,集装箱固然好用,但是如果它四面都光秃秃的,吊车还怎么把这个集装箱吊起来并摆放好呢?
所以,Pod 对象,其实就是容器的升级版。它对容器进行了组合,添加了更多的属性和字段。这就好比给集装箱四面安装了吊环,使得 Kubernetes 这架“吊车”,可以更轻松地操作它。
**而kubernetes操作这些pod的逻辑就是通过工作负载来实现的。 **
在看下kubernetes源码中的 pkg/controller 目录, 里面的内容就是我们控制器源码实现
这个目录下面的每一个控制器,都以独有的方式负责某种编排功能。而我们的 Deployment,正是这些控制器中的一种。
1 | $ cd kubernetes/pkg/controller/ |
控制器怎么编排?
之前我们说到, 控制器描述的是人们期望的pod的状态 ,但是往往事与愿违。应用程序实际运行的状态受很多因素的影响, 所以我们还是需要**根据实际的状态来调整, 调整成为我们希望的状态, 这就是容编排. **
用一段伪代码来表示编排动作。
1 | for { |
既然我们期望的状态是通过定义的yaml文件来完成的, 那么实际状态又是怎么来的呢 ? 虽然我们知道实际状态肯定是通过工作节点上获取到的。 但是如何获取? 获取什么才能判断 ?这些我们都不知道。
获取实际状态
常见的获取容器状态的手段就是kubelet 通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它自己感兴趣的信息,这些都是常见的实际状态的来源。
如何由实际状态达到期望状态 ?
其实这个上一章已经讲过了, 但是为了让大家理解更加深刻, 我们再来理解一遍
以 Deployment 部署nginx服务为例,我简单描述一下:
- Deployment 控制器从 Etcd 中获取到所有携带了“app: nginx”标签的 Pod,然后统计它们的数量,这就是实际状态;
- Deployment 对象的 Replicas 字段的值就是期望状态;
- Deployment 控制器将两个状态做比较,然后根据比较结果,确定是创建 Pod,还是删除已有的 Pod
可以看到,一个 Kubernetes 对象的主要编排逻辑,实际上是在第三步的“对比”阶段完成的。
这个操作,通常被叫作调谐(Reconcile)。这个调谐的过程,则被称作“Reconcile Loop”(调谐循环)或者“Sync Loop”(同步循环)。
实际上, kubernetes实现编排的方法就是通过deployment来对pod进行控制循环, 循环看他们的状态, 是否和预期的一致, 不一致要么删除一些已存在的pod ,要么重新创建一些pod。大致的思路就是这样, 但是具体的怎么删除, 怎么添加, 不同的控制器有着不同的实现逻辑。 我们下面要做的就是学习不同的控制器来深入每种编排思想。
注意, 这里大家不要被控制器(controller)和工作负载搞晕了, 工作负载是一组pod的集合。控制器是kubernetes提供来保证工作负载按照预期运行, 同时能够确保他们能够在集群中自动扩容和恢复。
另外再提一嘴, controller manager 是kubernetes提供的一个组件, 用于管理controller。 controller的种类由很多 ,上面有说(kubernetes源码中的/pkg/controller目录下)
Deployment , 作业副本与水平扩展
在这块, 我们具体介绍一下kubernetes的一种控制器, Deployment
前面其实有说。Deployment是一种工作负载,在Kubernetes中用于描述期望的状态。Deployment是用于部署、扩展和管理Pod的API对象,它代表用户期望的Pod集合的状态。Deployment会根据用户定义的期望状态自动管理Pod的生命周期,包括创建、更新和删除Pod。
Deployment的定义主要包括以下几个方面:
- Pod模板:定义了要创建的Pod的模板,包括容器的镜像、资源限制等。
- 副本数量:指定了期望运行的Pod副本数量。
- 更新策略:定义了Pod更新的方式,如滚动更新等。
- 选择器:用于选择哪些Pod应该由该Deployment管理。
通过Deployment,用户可以轻松地管理和扩展应用程序,同时确保应用程序的高可用性。Kubernetes会根据Deployment的定义自动处理Pod的创建、更新和删除等操作,以满足用户期望的状态
1 | apiVersion: apps/v1 |
这是我自己做练习的时候 通过deployment模板创建的一个nginx的yaml文件。这就是之前说的— 期望状态。
注意这里spec: - replicas: 2 这个其实就是ReplicaSet(也是一种控制器)的一个概念。
那么,在具体的实现上,这个 Deployment,与 ReplicaSet,以及 Pod 的关系是怎样的呢?
用一张图把它描述出来: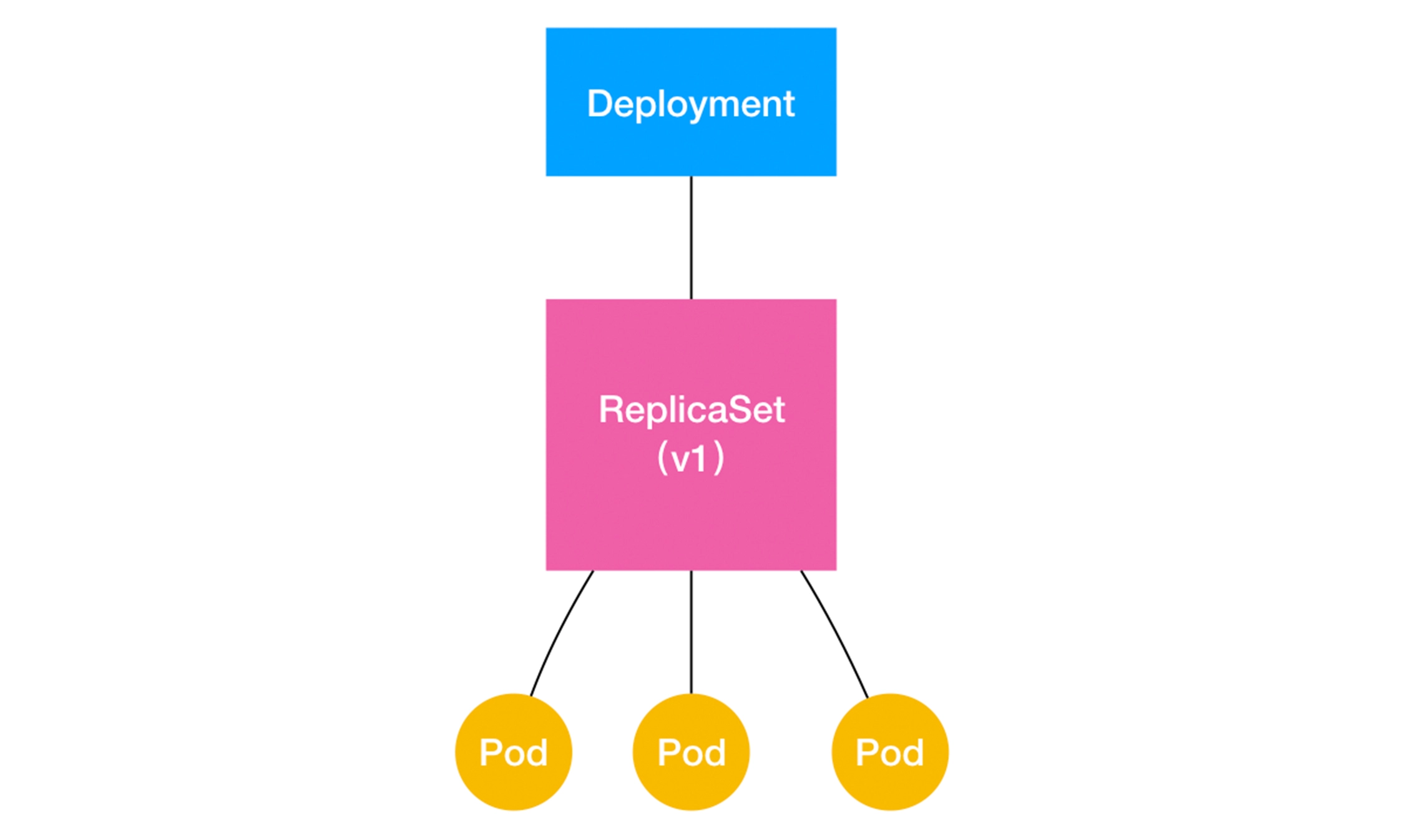
通过这张图,我们就很清楚地看到,一个定义了 replicas=3 的 Deployment,与它的 ReplicaSet,以及 Pod 的关系,实际上是一种“层层控制”的关系。
**ReplicaSet 【后面简称 rs】负责通过“控制器模式”,保证系统中 Pod 的个数永远等于指定的个数(比如,3 个)**。这也正是 Deployment 只允许容器的 restartPolicy=Always 的主要原因:只有在容器能保证自己始终是 Running 状态的前提下,ReplicaSet 调整 Pod 的个数才有意义。
而在此基础上,Deployment 同样通过“控制器模式”,来操作 ReplicaSet 的个数和属性,进而实现“水平扩展 / 收缩”和“滚动更新”这两个编排动作。
- 水平扩展、收缩: 就是通过replicas来控制pod个数
- 滚动更新 ? 好像就是更新策略….. 下面来研究一下滚动更新
滚动更新
以这个 Deployment 为例,来说说“滚动更新”的过程
在返回结果中,我们可以看到四个状态字段,它们的含义如下所示。
- READY:当前处于 Running 状态的 Pod 的个数;
- UP-TO-DATE:当前处于最新版本的 Pod 的个数,所谓最新版本指的是 Pod 的 Spec 部分与 Deployment 里 Pod 模板里定义的完全一致;
- AVAILABLE:当前已经可用的 Pod 的个数,即:既是 Running 状态,又是最新版本,并且已经处于 Ready(健康检查正确)状态的 Pod 的个数。
可以看到,只有这个 AVAILABLE 字段,描述的才是用户所期望的最终状态。
通过命令kubectl get deployment查看当前的控制器名称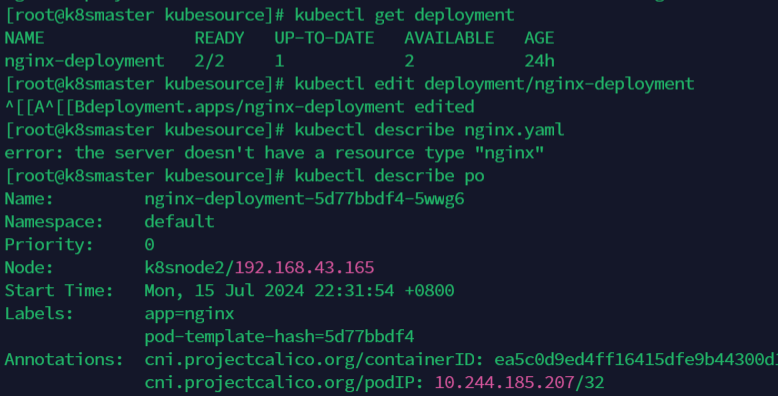
然后通过kubectl edit deployment/nginx-deployment 来进行修改etcd中对于这个deployment的内容。 他这里修改完之后就会重新提交上去。 然后就会进行滚动更新操作。
而 Kubernetes 项目还为我们提供了一条指令,让我们可以实时查看 Deployment 对象的状态变化。这个指令就是 kubectl rollout status: kubectl rollout status deployment/nginx-deployment
具体流程如下:
- 首先,当你修改了 Deployment 里的 Pod 定义之后,Deployment Controller 会使用这个修改后的 Pod 模板,创建一个新的 ReplicaSet(hash=1764197365),这个新的 ReplicaSet 的初始 Pod 副本数是:0。
- 然后,在 Age=24 s 的位置,Deployment Controller 开始将这个新的 ReplicaSet 所控制的 Pod 副本数从 0 个变成 1 个,即:“水平扩展”出一个副本。
- 紧接着,在 Age=22 s 的位置,Deployment Controller 又将旧的 ReplicaSet(hash=3167673210)所控制的旧 Pod 副本数减少一个,即:“水平收缩”成两个副本。
- 如此交替进行,新 ReplicaSet 管理的 Pod 副本数,从 0 个变成 1 个,再变成 2 个,最后变成 3 个。而旧的 ReplicaSet 管理的 Pod 副本数则从 3 个变成 2 个,再变成 1 个,最后变成 0 个。这样,就完成了这一组 Pod 的版本升级过程。
像这样,将一个集群中正在运行的多个 Pod 版本,交替地逐一升级的过程,就是“滚动更新”。
当然, 在更新的同时, pod还会有健康检查机制 ,如果fail了, 那么运维人员就会接入。当然, 旧的pod依然在运行, 并不会对现网的业务造成任何影响。
而为了进一步保证服务的连续性,Deployment Controller 还会确保,在任何时间窗口内,只有指定比例的 Pod 处于离线状态。同时,它也会确保,在任何时间窗口内,只有指定比例的新 Pod 被创建出来。这两个比例的值都是可以配置的,默认都是 DESIRED 值的 25%。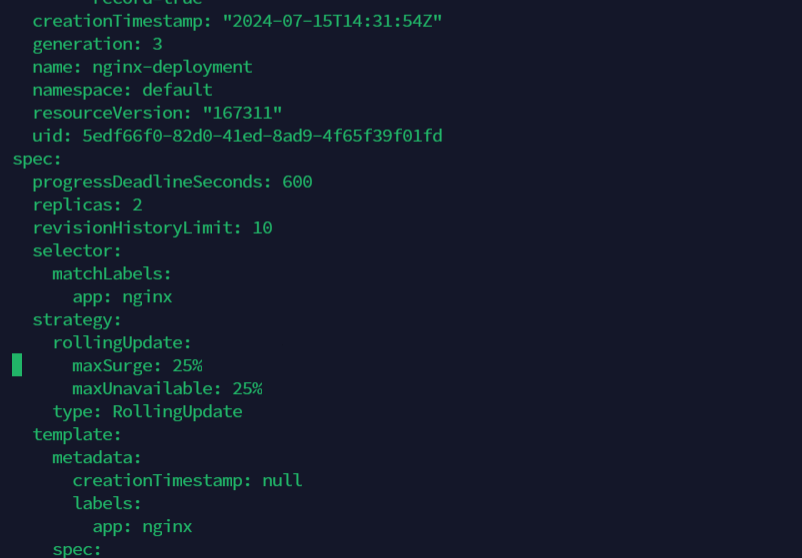
所以,在上面这个 Deployment 的例子中,它有 3 个 Pod 副本,那么控制器在“滚动更新”的过程中永远都会确保至少有 2 个 Pod 处于可用状态,至多只有 4 个 Pod 同时存在于集群中。这个策略,是 Deployment 对象的一个字段,名叫 RollingUpdate
RollingUpdate中,对于最大删除有着百分比的要求。
两个配置还可以用前面我们介绍的百分比形式来表示,比如:maxUnavailable=50%,指的是我们最多可以一次删除“50%*DESIRED 数量”个 Pod。
综上, 我们可以扩展一下 Deployment、ReplicaSet 和 Pod 的关系图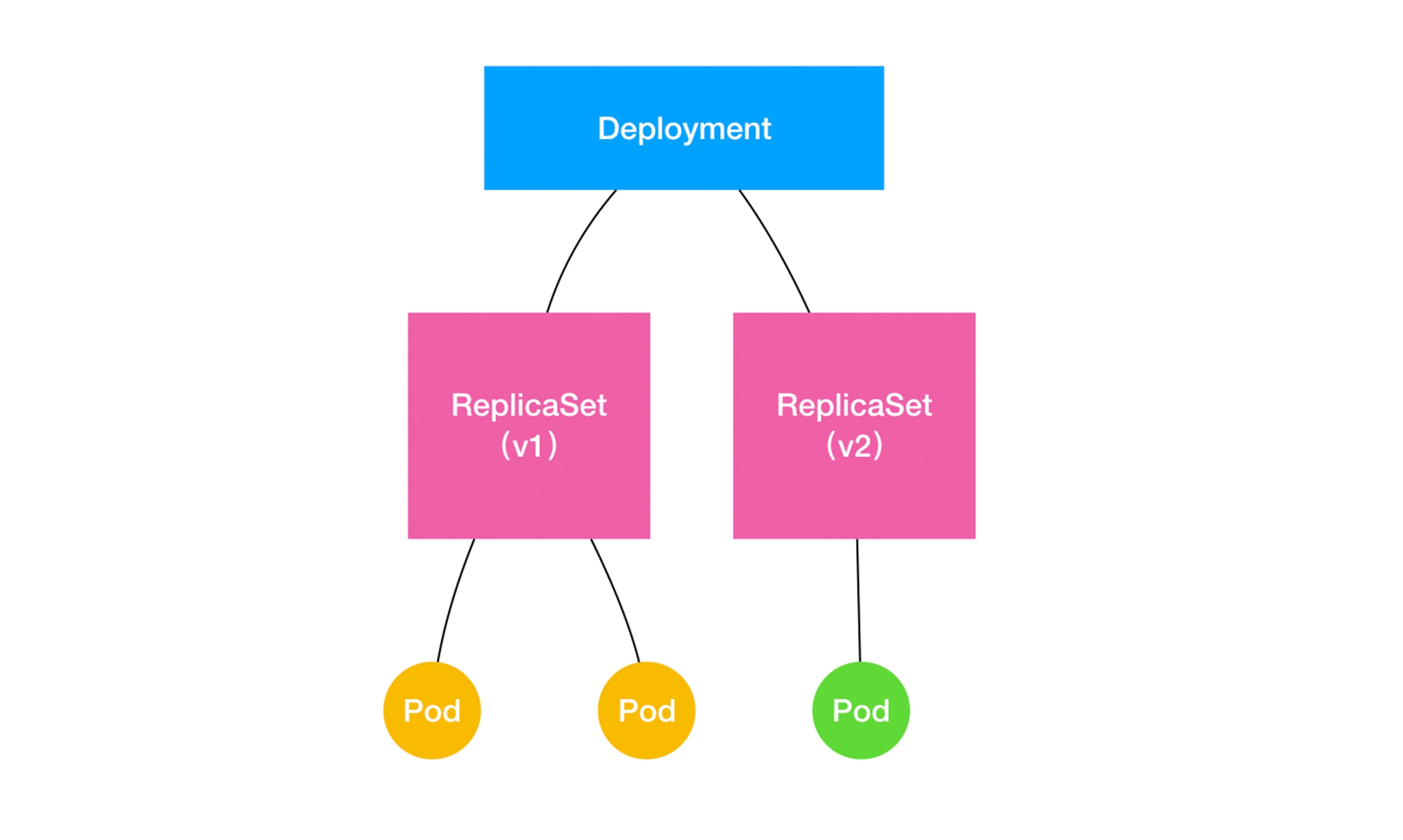
Deployment 的控制器,实际上控制的是 ReplicaSet 的数目,以及每个 ReplicaSet 的属性。
而一个应用的版本,对应的正是一个 ReplicaSet;这个版本应用的 Pod 数量,则由 ReplicaSet 通过它自己的控制器(ReplicaSet Controller)来保证。
通过这样的多个 ReplicaSet 对象,Kubernetes 项目就实现了对多个“应用版本”的描述。
Deployment 对应用进行版本控制的具体原理
这一次,我会使用一个叫 kubectl set image 的指令,直接修改 nginx-deployment 所使用的镜像。这个命令的好处就是,你可以不用像 kubectl edit 那样需要打开编辑器。$ kubectl set image deployment/nginx-deployment nginx=nginx:1.91
由于这个 nginx:1.91 镜像在 Docker Hub 中并不存在,所以这个 Deployment 的“滚动更新”被触发后,会立刻报错并停止。
通过这个返回结果,我们可以看到,新版本的 ReplicaSet(hash=2156724341)的“水平扩展”已经停止。而且此时,它已经创建了两个 Pod,但是它们都没有进入 READY 状态。这当然是因为这两个 Pod 都拉取不到有效的镜像。
与此同时,旧版本的 ReplicaSet(hash=1764197365)的“水平收缩”,也自动停止了。此时,已经有一个旧 Pod 被删除,还剩下两个旧 Pod。
我们只需要执行一条 kubectl rollout undo 命令,就能把整个 Deployment 回滚到上一个版本:$ kubectl rollout undo deployment/nginx-deployment
更进一步地,如果我想回滚到更早之前的版本,要怎么办呢?
**首先,我需要使用 kubectl rollout history 命令,查看每次 Deployment 变更对应的版本。而由于我们在创建这个 Deployment 的时候,指定了–record 参数,所以我们创建这些版本时执行的 kubectl 命令,都会被记录下来。
**然后,我们就可以在 kubectl rollout undo 命令行最后,加上要回滚到的指定版本的版本号,就可以回滚到指定版本了。这个指令的用法如下:kubectl rollout undo deployment/nginx-deployment --to-revision=2
这样,Deployment Controller 还会按照“滚动更新”的方式,完成对 Deployment 的降级操作。
Tip:
Deployment 对象有一个字段,叫作 spec.revisionHistoryLimit,就是 Kubernetes 为 Deployment 保留的“历史版本”个数。所以,如果把它设置为 0,你就再也不能做回滚操作了。




