
声明式Api及其实际应用
声明式API的交互
这篇文章, 我将按照自己的理解结合我阅读过的文章给大家讲讲关于声明式API这个概念
声明式API是一种编程接口设计模式,在Kubernetes中,它允许用户通过描述资源的期望状态来与系统进行交互,而不是像传统的命令式API那样详细指定实现期望状态的具体步骤。所以, 在介绍声明式API与系统交互之前, 我们先来看看传统的命令式交互是怎么实现的,它的实现手段与声明式的有什么不同? 为什么要转为声明式api的方式来交互呢? 等等一系列的问题, 下面我都会一一列举
传统的交互方式
首先, 我们看几个常用的传统式交互
1 | # 创建操作 |
上面两个式最典型的传统命令式交互的方式。
在创建pod的时候通过create ,如果对现有的pod需要进行改动的话, 直接通过 vim 修改之前的yaml文件, 然后再当前目录下通过 replace命令进行修改。 通过这样一套命令算是完成了对pod最基本的两个动作。 但是在kubernetes中 最核心的概念是什么? 当然是容器编排。
那么这两个命令是怎么体现出来容器编排这个概念的? 其实它并没有很好的体现出来, 所以他们是我们最不愿意使用的方式。
有人可能会说如果我在nginx.yaml通过Deployment 或者DaemonSet等等控制器对象来实现的就是容器编排。 这种说法也没错 ,但是为什么我说没有很好的体现出来呢? 因为虽然
kubectl create可以用于创建 Deployment 并通过控制器来管理容器,但是这样创建最终还是通过声明式,而不是命令式 同时它在以下方面存在一些局限性:
- 幂等性和更新
- 问题:
kubectl create主要用于创建资源,不能直接用于更新已有资源。如果资源已存在,执行该命令会报错。
- 版本控制和配置管理
- 问题:
kubectl create的命令结果是即时的,并不提供对配置文件版本的管理。现象就是无法找到历史的操作记录。 同时 无法轻松查看或回溯具体的创建时间、执行人及配置内容。除非手动记录
所以,上述这种 命令式配置文件操作 很难适配当前云原生时代下的微服务容器编排。
声明式API的交互
说了一堆命令式交互的坏处, 那么现在还得来说说声明式的好处 ,此消彼长。 大家当然就知道该用什么不该用什么了吧。下面我来列列
- 幂等性:无论执行多少次,资源都会被调整到期望状态,不会产生副作用。
- 适用于更新:可以用于创建和更新资源,配置文件的变更会自动应用到现有资源。
- 声明式管理:通过配置文件管理资源状态,自动处理创建、更新和删除操作。
- 幂等性:确保资源最终状态与配置文件一致,多次执行不会有副作用。
- 自动化管理:适合持续集成/持续交付(CI/CD)和基础设施即代码(IaC)场景。
- 易于版本控制:配置文件可以存储在版本控制系统中,便于追踪和回滚。
上面的这些特点是我照搬的…..
最直观的体现就是通过kubectl apply -f nginx.yaml无论你是在更新还是在新建, 也不管node里面有没有这个pod, 都可以用它来操作。为什么呢?
我之前的文章中讲过, kubernetes在执行apply命令的时候是通过一种检查更新的机制来执行的, 前面说到的有段伪代码
1 | for { |
这也是kubectl apply这种声明式api操作配置文件为什么更新和创建都可以用它。
区别 + 引出重点 ★★★★
可是,它跟 kubectl replace 命令有什么本质区别吗?
实际上,你可以简单地理解为
kubectl replace的执行过程,是使用新的 YAML 文件中的 API 对象,替换原有的 API 对象;kubectl apply,则是执行了一个对原有 API 对象的 PATCH 操作。
类似地,kubectl set image 和 kubectl edit 也是对已有 API 对象的修改。
kube-apiserver 在响应命令式请求(比如,kubectl replace)的时候,一次只能处理一个写请求,否则会有产生冲突的可能。
而对于声明式请求(比如,kubectl apply),一次能处理多个写操作,并且具备 Merge 能力。
这种区别,可能乍一听起来没那么重要。但是一旦你的系统越来越复杂,需要维护的变更越来越多, 你就能体会到这种merge的好处了。下面我就来带大家看看它的真实用处
声明式API的实际使用意义-服务治理★★★★★
在云原生时代, 微服务这个名词一直围绕着我们,Service Mesh 这个新概念也是如火如荼的被大家讨论,应用着。
好像大家谁不懂微服务就不懂技术, 在技术圈子是这样的鄙视链
Istio这个开源项目的出现, 更是让微服务、服务发现、服务治理…这些名词都被大家熟知着。
而 Istio 项目,实际上就是一个基于 Kubernetes 项目的微服务治理框架。它的架构非常清晰,如下所示: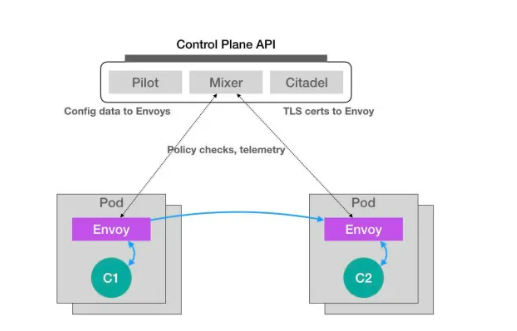
在上面这个架构图中,我们不难看到 Istio 项目架构的核心所在(istio是服务网格平台, 他和)。Istio 最根本的组件,是运行在每一个应用 Pod 里的Envoy sidecar代理容器。
这个 Envoy 项目是 Lyft 公司推出的一个高性能 C++** 网络代理**,也是 Lyft 公司对 Istio 项目的唯一贡献。
**在Istio中,Envoy作为sidecar代理,与每个服务实例一起部署,负责拦截所有出入服务的流量,并负责实施策略和收集遥测数据 **。 这在微服务中是非常重要。 后续我会介绍
我们知道,Pod 里的所有容器都共享同一个 NetwAork Namespace。所以,Envoy 容器就能够通过配置 Pod 里的 iptables 规则,把整个 Pod 的进出流量接管下来。
这段话需要细细的品一下,我们集群的流量调度是如何管理的等等
这时候,Istio 的控制层(Control Plane)里的 Pilot 组件,就能够通过调用每个 Envoy 容器的 API,对这个 Envoy 代理进行配置,从而实现微服务治理。
服务治理的实例
以这个架构图为例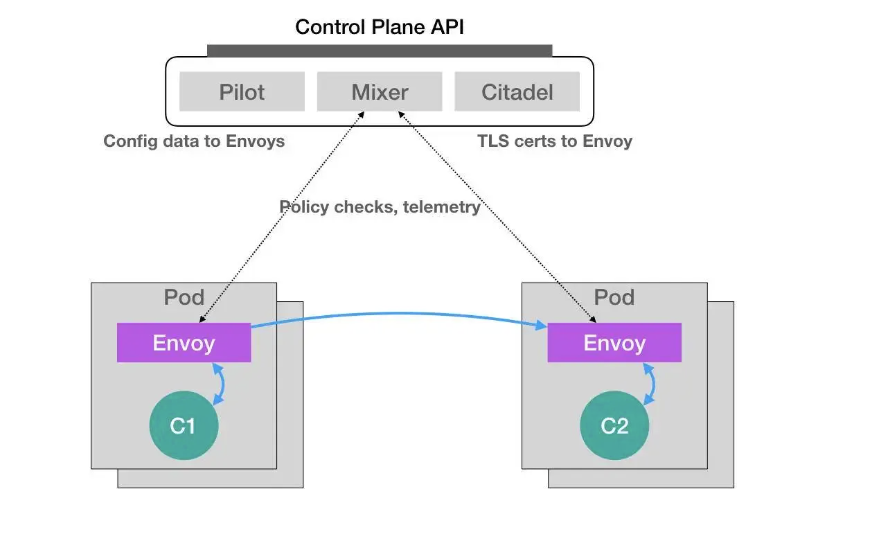
简单说下这个图
- Pilot组件配置数据到Envoy。
- Mixer组件执行策略检查和遥测。
- Citadel组件提供TLS证书给Envoy。
Envoy之间通过Pod进行通信,形成一个分布式系统。
假设这个 Istio 架构图左边的 Pod 是已经在运行的应用,而右边的 Pod 则是我们刚刚上线的应用的新版本。这时候,Pilot 通过调节这两 Pod 里的 Envoy 容器的配置,从而将 90% 的流量分配给旧版本的应用,将 10% 的流量分配给新版本应用,并且,还可以在后续的过程中随时调整。这样,一个典型的“灰度发布”的场景就完成了。比如,Istio 可以调节这个流量从 90%-10%,改到 80%-20%,再到 50%-50%,最后到 0%-100%,就完成了这个灰度发布的过程。
上述部分是引用张磊老师文章的
更重要的是,在整个微服务治理的过程中,无论是对 Envoy 容器的部署,还是像上面这样对 Envoy 代理的配置,用户和应用都是完全“无感”的。
无感知更新- 动态准入控制 (DAC)
Istio 项目明明需要在每个 Pod 里安装一个 Envoy Sidecar 容器,又怎么能做到“无感”的呢?
实际上,Istio 项目使用的,是 Kubernetes 中的一个非常重要的功能,叫作 Dynamic Admission Control(动态准入控制)。
kubernetes的这个功能它允许管理员在运行时动态地控制哪些Pod可以被调度到集群中。
在 Kubernetes 项目中,当一个 Pod 或者任何一个 API 对象被提交给 API Server 之后,总有一些“初始化”性质的工作需要在它们被 Kubernetes 项目正式处理之前进行。(比如,自动为所有 Pod 加上某些标签)而这个“初始化”操作的实现,借助的是一个叫作 Admission(准入) 的功能。它其实是 Kubernetes 项目里一组被称为 Admission Controller 的代码,可以选择性地被编译进 APIServer 中,在 API 对象创建之后会被立刻调用到。
但这就意味着,如果你现在想要添加一些自己的规则到 Admission Controller,就会比较困难。因为,这要求重新编译并重启 APIServer。显然,这种使用方法对 Istio 来说,影响太大了。因为Istio项目想的就是通过动态准入的方式来添加
详解DAC 机制
Kubernetes 项目为我们额外提供了一种“热插拔”式的 Admission 机制,它就是 Dynamic Admission Control(动态准入控制),也叫作:Initializer
现在,我给你举个例子。比如,我有如下所示的一个应用 Pod:
1 | apiVersion: v1 |
可以看到,这个 Pod 里面只有一个用户容器,叫作:myapp-container。
接下来,Istio 项目要做的,就是在这个 Pod YAML 被提交给 Kubernetes 之后,在它对应的 API 对象里自动加上 Envoy 容器的配置,使这个对象变成如下所示的样子:
1 | apiVersion: v1 |
可以看到,被 Istio 处理后的这个 Pod 里,除了用户自己定义的 myapp-container 容器之外,多出了一个叫作 envoy 的容器,它就是 Istio 要使用的 Envoy 代理。
那么,Istio 又是如何在用户完全不知情的前提下完成这个操作的呢?
相信学过Java的人对于自动注入非常了解吧
Istio 要做的,就是编写一个用来为 Pod“自动注入”Envoy 容器的 Initializer。
首先,Istio 会将这个 Envoy 容器本身的定义,以 ConfigMap 的方式保存在 Kubernetes 当中。这个 ConfigMap(名叫:envoy-initializer)的定义如下所示:
1 | apiVersion: v1 |
代码内容引用 张磊老师 文章
这个 ConfigMap 的 data 部分,正是一个 Pod 对象的一部分定义。其中,我们可以看到 Envoy 容器对应的 containers 字段,以及一个用来声明 Envoy 配置文件的 volumes 字段。
不难想到,Initializer 要做的工作,就是把这部分 Envoy 相关的字段,自动添加到用户提交的 Pod 的 API 对象里。可是,用户提交的 Pod 里本来就有 containers 字段和 volumes 字段,所以 Kubernetes 在处理这样的更新请求时,就必须使用类似于 git merge 这样的操作,才能将这两部分内容合并在一起。( 在前面我说过 )
所以说,在 Initializer 更新用户的 Pod 对象的时候,必须使用 PATCH API 来完成。而这种 PATCH API,正是声明式 API 最主要的能力。
机制的原理及其实现方式
先给大家一段伪代码,让大家了解一下基本流程,接着我会剖析整个流程来详细讲解
1 | for { |
根据上面的流程, 我们以一个编写好的 Initializer,作为一个 Pod 部署在 Kubernetes 中。然后来过一遍这个流程。
这个 Pod 的定义非常简单,如下所示:
1 | apiVersion: v1 |
我们可以看到,这个 envoy-initializer 使用的 envoy-initializer:0.0.1 镜像,就是一个事先编写好的“自定义控制器”(Custom Controller)
- 上面我就给大家提供过一个伪代码。一个 Kubernetes 的控制器,实际上就是一个“死循环”:它不断地获取“实际状态”,然后与“期望状态”作对比,并以此为依据决定下一步的操作。
而 Initializer 的控制器,不断获取到的“实际状态”,就是用户新创建的 Pod。而它的“期望状态”,则是:这个 Pod 里被添加了 Envoy 容器的定义。这个控制逻辑,如下所示:
1 | for { |
- 如果这个 Pod 里面已经添加过 Envoy 容器,那么就“放过”这个 Pod,进入下一个检查周期。
- 而如果还没有添加过 Envoy 容器的话,它就要进行 Initialize 操作了,即:修改该 Pod 的 API 对象(doSomething 函数)。
Istio 要往这个 Pod 里合并的字段,正是我们之前保存在
name=envoy-initializer这个 ConfigMap 里的数据(即:它的 data 字段的值. 上面有的)。
- 在 Initializer 控制器的工作逻辑里,它首先会从 APIServer 中拿到这ConfigMap:
1 | func doSomething(pod) { |
- 然后,把这个 ConfigMap 里存储的 containers 和 volumes 字段,直接添加进一个空的 Pod 对象里:
1 | func doSomething(pod) { |
现在,关键来了。
- Kubernetes 的 API 库,为我们提供了一个方法
TwoWayMergePatch,使得我们可以直接使用新旧两个 Pod 对象,生成patch数据:
1 | func doSomething(pod) { |
有了这个 TwoWayMergePatch 方法生成的数据之后,Initializer 的代码就可以使用这个 patch 的数据patchBytes,调用 Kubernetes 的 Client,发起一个 PATCH 请求。
这样,一个用户提交的 Pod 对象里,就会被自动加上 Envoy 容器相关的字段。上述就是通过DAC来实现 用户无感知注入的全部流程。
当然这种将配置插入业务pod的方式不止一种 ,还可以通过配置的方式来实现。 下面我们来快速过下
通过配置的方式
当然,Kubernetes 还允许你通过配置,来指定要对什么样的资源进行这个 Initialize 操作,比如下面这个例子:
提醒大家一下, 这个InitializerConfiguration使用的apiVersion是以及被弃用了的, 别直接照常然后去运行。 这里我只是按照学习到的思想做分享,思想到落地还有很大一步路要走
1 | apiVersion: admissionregistration.k8s.io/v1 |
相信这个InitializerConfiguration 大家应该没见过吧, 虽然我也没见过 ,但可以查呀。
没错InitializerConfiguration也是 Kubernetes 中的一个特性,它允许管理员定义一组初始化器(Initializer),这些初始化器会在创建新的资源对象(如 Pod、Deployment 等)时自动执行。初始化器可以用于执行各种任务,例如注入环境变量、修改资源标签、验证资源内容等。
这个配置,就意味着 Kubernetes 要对所有的 Pod 都会自动的进行这个 Initialize 操作,并且,我们指定了负责这个操作的 Initializer,名叫:envoy-initializer。
**而一旦这个 **InitializerConfiguration 被创建,Kubernetes 就会把这个 Initializer 的名字,加在所有新创建的 Pod 的 Metadata 上,格式如下所示:
1 | apiVersion: v1 |
所以, 可以看到,每一个新创建的 Pod,都会自动携带了 metadata.initializers.pending 的 Metadata 信息。
这个 Metadata,正是接下来 Initializer 的控制器判断这个 Pod 有没有执行过自己所负责的初始化操作的重要依据(也就是前面伪代码中 isInitialized() 方法的含义: 检查是否已经初始化过)。
这也就意味着,当你在 Initializer 里完成了要做的操作后,一定要记得将这个 metadata.initializers.pending 标志清除掉。这一点,你在编写 Initializer 代码的时候一定要非常注意。
此外,除了上面的配置方法,你还可以在具体的 Pod 的 Annotation 里添加一个如下所示的字段,从而声明要使用某个 Initializer:
1 | apiVersion: v1 |
在这个 Pod 里,我们添加了一个 Annotation,写明: initializer.kubernetes.io/envoy=true。这样,就会使用到我们前面所定义的 envoy-initializer 了。
以上,就是关于 Initializer 最基本的工作原理和使用方法了。相信你此时已经明白,Istio 项目的核心,就是由无数个运行在应用 Pod 中的 Envoy 容器组成的服务代理网格。这也正是 Service Mesh 的含义。
Kubernetes“声明式 API”的独特之处
而这个机制得以实现的原理,正是借助了 Kubernetes 能够对 API 对象进行在线更新的能力,这也正是 Kubernetes“声明式 API”的独特之处:
- 首先,所谓“声明式”,指的就是我只需要提交一个定义好的 API 对象来“声明”,我所期望的状态是什么样子。
- 其次,“声明式 API”允许有多个 API 写端,以 PATCH 的方式对 API 对象进行修改,而无需关心本地原始 YAML 文件的内容。
- 最后,也是最重要的,有了上述两个能力,Kubernetes 项目才可以基于对 API 对象的增、删、改、查,在完全无需外界干预的情况下,完成对“实际状态”和“期望状态”的调谐(Reconcile)过程。
所以说,声明式 API,才是 Kubernetes 项目编排能力“赖以生存”的核心所在
此外,不难看到,无论是对 sidecar 容器的巧妙设计,还是对 Initializer 的合理利用,Istio 项目的设计与实现,其实都依托于 Kubernetes 的声明式 API 和它所提供的各种编排能力。可以说,Istio 是在 Kubernetes 项目使用上的一位“集大成者”。
ps: 要知道,一个 Istio 项目部署完成后,会在 Kubernetes 里创建大约 43 个 API 对象。
所以,Kubernetes 社区也看得很明白:Istio 项目有多火热,就说明 Kubernetes 这套“声明式 API”有多成功
而在使用 Initializer 的流程中,最核心的步骤,莫过于 Initializer“自定义控制器”的编写过程。它遵循的,正是标准的“Kubernetes 编程范式”,即:
如何使用控制器模式,同 Kubernetes 里 API 对象的“增、删、改、查”进行协作,进而完成用户业务逻辑的编写过程。





