
深入解析容器网络
容器网络
在使用kubernetes之前, 最为火热的技术就是Docker技术了。 它完成了从虚拟机时代的过度,是走向云原生时代的开端。 但是由于docker的故步自封导致被google的开源的kubernetes后来居上, 现在的Docker虽然在积极改进, 但是主流大势已经被kubernetes掌握, 所以也只能起到助力作用。
回归正题, 在kubernetes的服务发现, 服务网格等技术火热之前, 是怎么来实现容器之间的通信呢 ?本文我们就来探讨一下。
什么是容器网络及它解决了什么问题 ?
容器网络利用Linux的network namespace实现对网络资源的隔离,每个容器都有自己的网络栈,包括网卡、回环设备、路由表和iptables规则。
**容器网络需要解决的主要问题包括容器IP的分配、容器之间的互相访问、容器如何访问主机外部网络、以及外部网络如何访问到容器内部。 **
容器网络实现技术
容器网络的实现主要借助了下面两种技术。一个是 Veth Pair ,另一个是Bridge 网桥
- Veth Pair:用于实现不同Network Namespace之间的通信。
- Bridge:Linux中的虚拟交换机,用于连接不同的Network Namespace
这里先暂时理解为实体的电脑的多个网卡和 电脑内置交换机(自造词)。 但其实他们之间还是有很大差异的, 后面我再详细解释下他们为什么有这么大差异。
后面我在来详细说下, 先有这个概念
探讨容器网络
其实, 虽然上面说到了使用linux的namespace规则实现对网络资源的隔离, 但是作为一个容器,它可以声明直接使用宿主机的网络栈(–net=host),即:不开启 Network Namespace,比如:$ docker run –d –net=host --name nginx-host nginx
在这种情况下,这个容器启动后,直接监听的就是宿主机的 80 端口。
像这样直接使用宿主机网络栈的方式,虽然可以为容器提供良好的网络性能,但也会不可避免地引入共享网络资源的问题,比如端口冲突。所以,在大多数情况下,我们都希望容器进程能使用自己 Network Namespace 里的网络栈,即:拥有属于自己的 IP 地址和端口。
为了理解这个问题,你其实可以把每一个容器看做一台主机,它们都有一套独立的“网络栈”。
如果你想要实现两台主机之间的通信,最直接的办法,就是把它们用一根网线连接起来;而如果你想要实现多台主机之间的通信,那就需要用网线,把它们连接在一台交换机上。
在** Linux 中,能够起到虚拟交换机作用的网络设备,是网桥(Bridge**)。它是一个工作在数据链路层(Data Link)的设备,主要功能是根据 MAC 地址学习来将数据包转发到网桥的不同端口(Port)上
简介网桥Bridge
bridge网桥是一种虚拟网络设备,用于连接不同的网络设备和容器,使它们能够在同一网络中进行通信。Bridge网桥充当一个中介,将容器与主机网络连接起来,使容器可以与外部网络和其他容器进行通信。
为了实现上述目的,Docker 项目会默认在宿主机上创建一个名叫 docker0 的网桥,凡是连接在 docker0 网桥上的容器,就可以通过它来进行通信。
可是,我们又该如何把这些容器“连接”到 docker0 网桥上呢?
这时候,我们就需要使用一种名叫** Veth Pair 的虚拟设备了**。
简介Veth Pair
veth pair 是成对出现的一种虚拟网络设备接口,一端连着网络协议栈,一端彼此相连。veth pair 总是成对出现的,从一端进入的数据包将会在另一端出现。我们可以把 veth pair 看成一条网线两端连接的两张以太网卡。只要将 veth pair 每一段分别接入不同的
Namespace,那么这两个Namespace就可以实现互通了
Veth Pair 设备的特点是:它被创建出来后,总是以两张虚拟网卡(Veth Peer)的形式成对出现的。并且,从其中一个“网卡”发出的数据包,可以直接出现在与它对应的另一张“网卡”上,哪怕这两个“网卡”在不同的 Network Namespace 里。
这就使得 Veth Pair 常常被用作连接不同 Network Namespace 的“网线”。
举例来说Veth Pair
比如,现在我们启动了一个叫作 nginx-1 的容器,然后进入到这个容器中查看一下它的网络设备:
1 | # 在宿主机上 |
可以看到,这个容器里有一张叫作 eth0 的网卡,它正是一个 Veth Pair 设备在容器里的这一端。
通过 route 命令查看 nginx-1 容器的路由表,我们可以看到,这个 eth0 网卡是这个容器里的默认路由设备;所有对 172.17.0.0/16 网段的请求,也会被交给 eth0 来处理(第二条 172.17.0.0 路由规则)。
而这个 Veth Pair 设备的另一端,则在宿主机上。你可以通过查看宿主机的网络设备看到它,如下所示:
1 | # 在宿主机上 |
通过 ifconfig 命令的输出,你可以看到,nginx-1 容器对应的 Veth Pair 设备,在宿主机上是一张虚拟网卡。它的名字叫作 veth9c02e56。并且,通过 brctl show 的输出,你可以看到这张网卡被“插”在了 docker0 上。
这时候,如果我们再在这台宿主机上启动另一个 Docker 容器,比如 nginx-2
1 | $ docker run –d --name nginx-2 nginx |
你就会发现一个新的、名叫 vethb4963f3 的虚拟网卡,也被“插”在了 docker0 网桥上。
这时候,如果你在 nginx-1 容器里 ping 一下 nginx-2 容器的 IP 地址(172.17.0.3),就会发现同一宿主机上的两个容器默认就是相互连通的。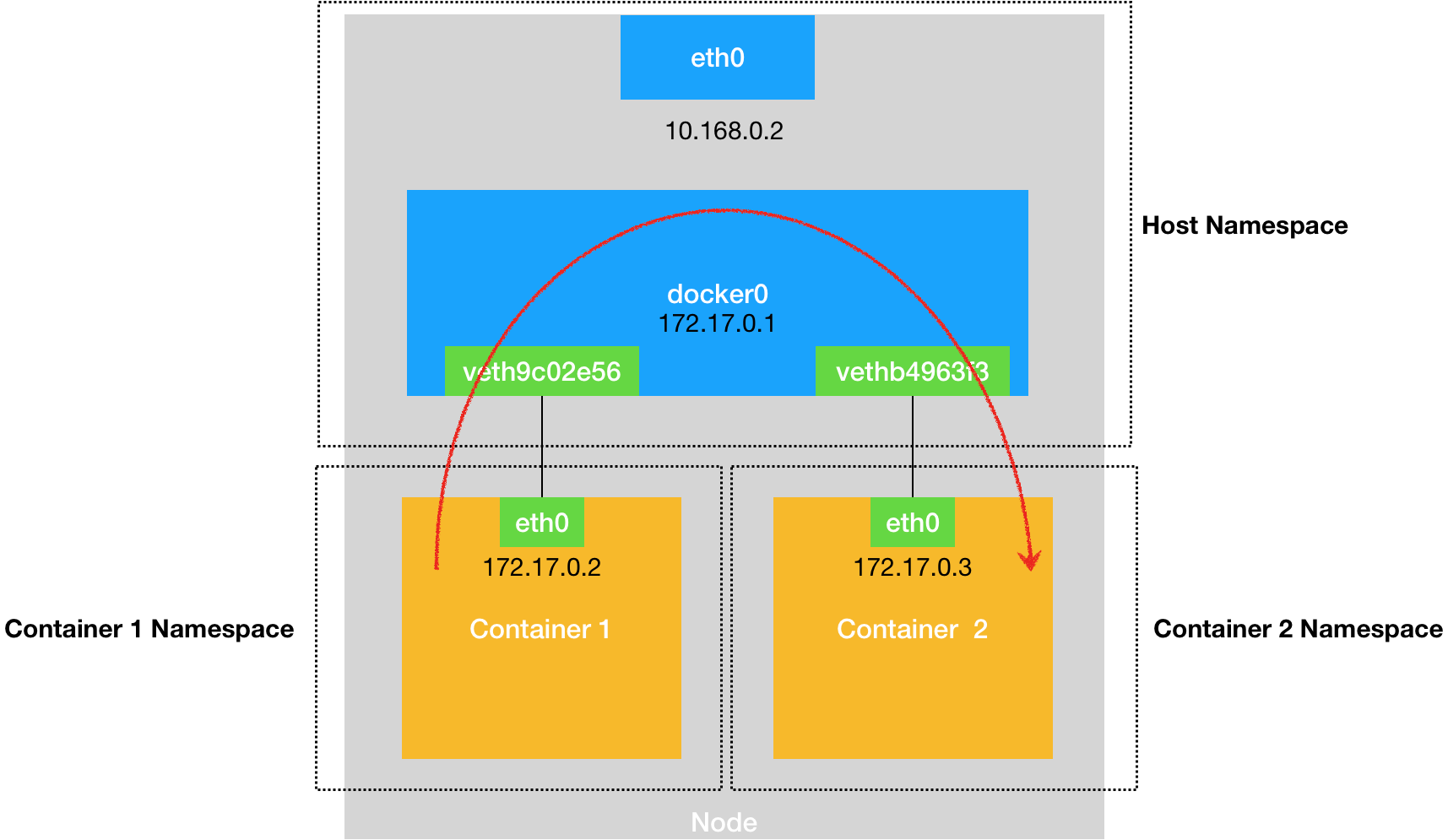
需要注意的是,在实际的数据传递时,上述数据的传递过程在网络协议栈的不同层次,都有 Linux 内核 Netfilter 参与其中。
简述网桥Bridge
熟悉了 docker0 网桥的工作方式,你就可以理解,在默认情况下,被限制在 Network Namespace 里的容器进程,实际上是通过 Veth Pair 设备 + 宿主机网桥的方式,实现了跟同其他容器的数据交换。
与之类似地,当你在一台宿主机上,访问该宿主机上的容器的 IP 地址时,这个请求的数据包,也是先根据路由规则到达 docker0 网桥,然后被转发到对应的 Veth Pair 设备,最后出现在容器里。这个过程的示意图,如下所示: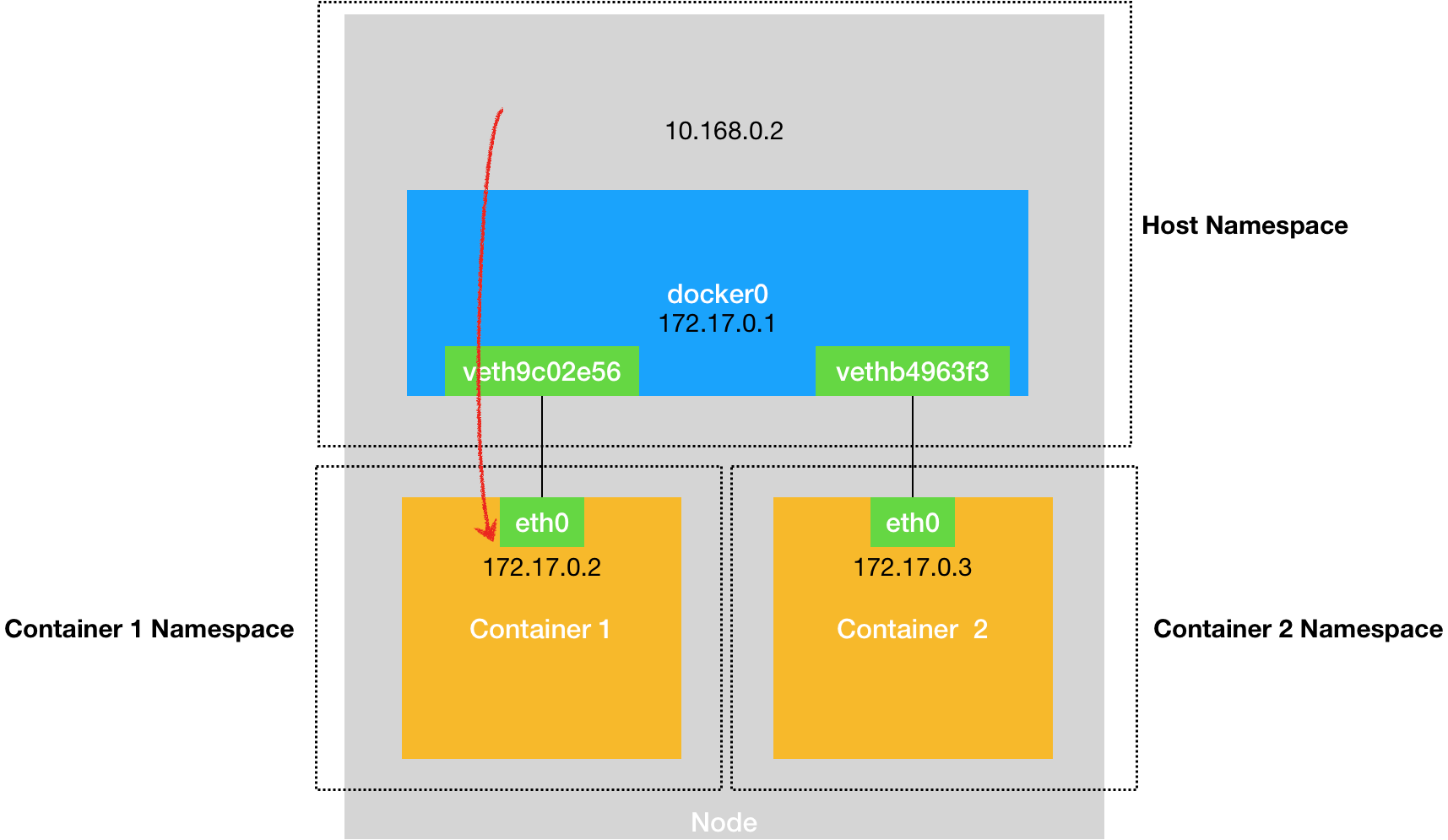
同样地,当一个容器试图连接到另外一个宿主机时,比如:ping 10.168.0.3,它发出的请求数据包,首先经过 docker0 网桥出现在宿主机上。然后根据宿主机的路由表里的直连路由规则(10.168.0.0/24 via eth0)),对 10.168.0.3 的访问请求就会交给宿主机的 eth0 处理。
所以接下来,这个数据包就会经宿主机的 eth0 网卡转发到宿主机网络上,最终到达 10.168.0.3 对应的宿主机上。当然,这个过程的实现要求这两台宿主机(本身就是一个宿主机)本身是连通的。这个过程的示意图,如下所示: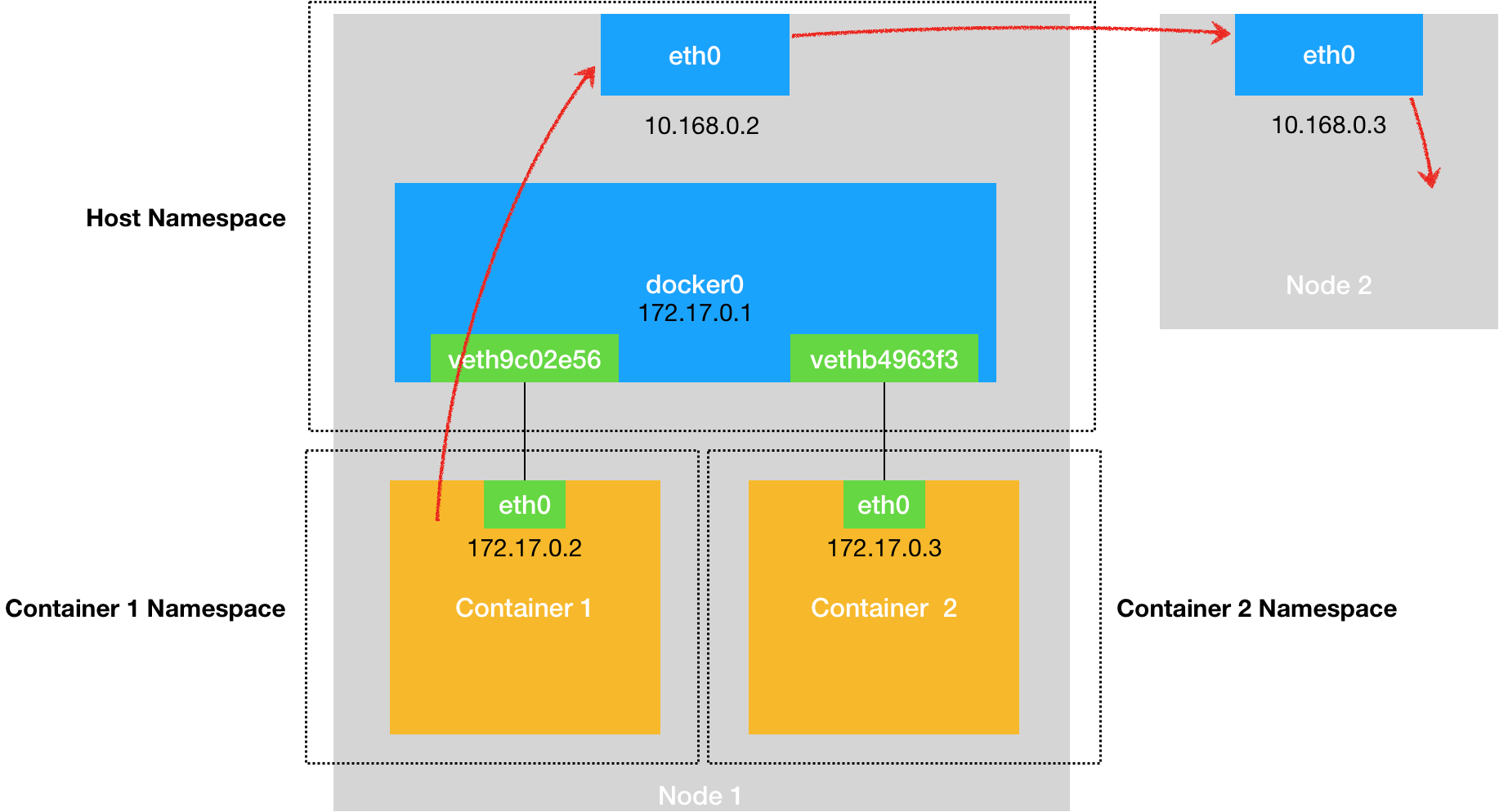
所以说,当你遇到容器连不通“外网”的时候,你都应该先试试 docker0 网桥能不能 ping 通,然后查看一下跟 docker0 和 Veth Pair 设备相关的 iptables 规则是不是有异常,往往就能够找到问题的答案了。
不过,在最后一个“Docker 容器连接其他宿主机”的例子里,你可能已经联想到了这样一个问题:如果在另外一台宿主机(比如:10.168.0.3)上,也有一个 Docker 容器。那么,我们的 nginx-1 容器又该如何访问它呢?这个问题,**其实就是容器的“跨主通信”问题。 **
跨主机通信的问题怎么解决 ?
在 Docker 的默认配置下,一台宿主机上的 docker0 网桥,和其他宿主机上的 docker0 网桥,没有任何关联,它们互相之间也没办法连通。所以,连接在这些网桥上的容器,自然也没办法进行通信了。
如果我们通过软件的方式,创建一个整个集群“公用”的网桥,然后把集群里的所有容器都连接到这个网桥上,不就可以相互通信了吗?类似这样。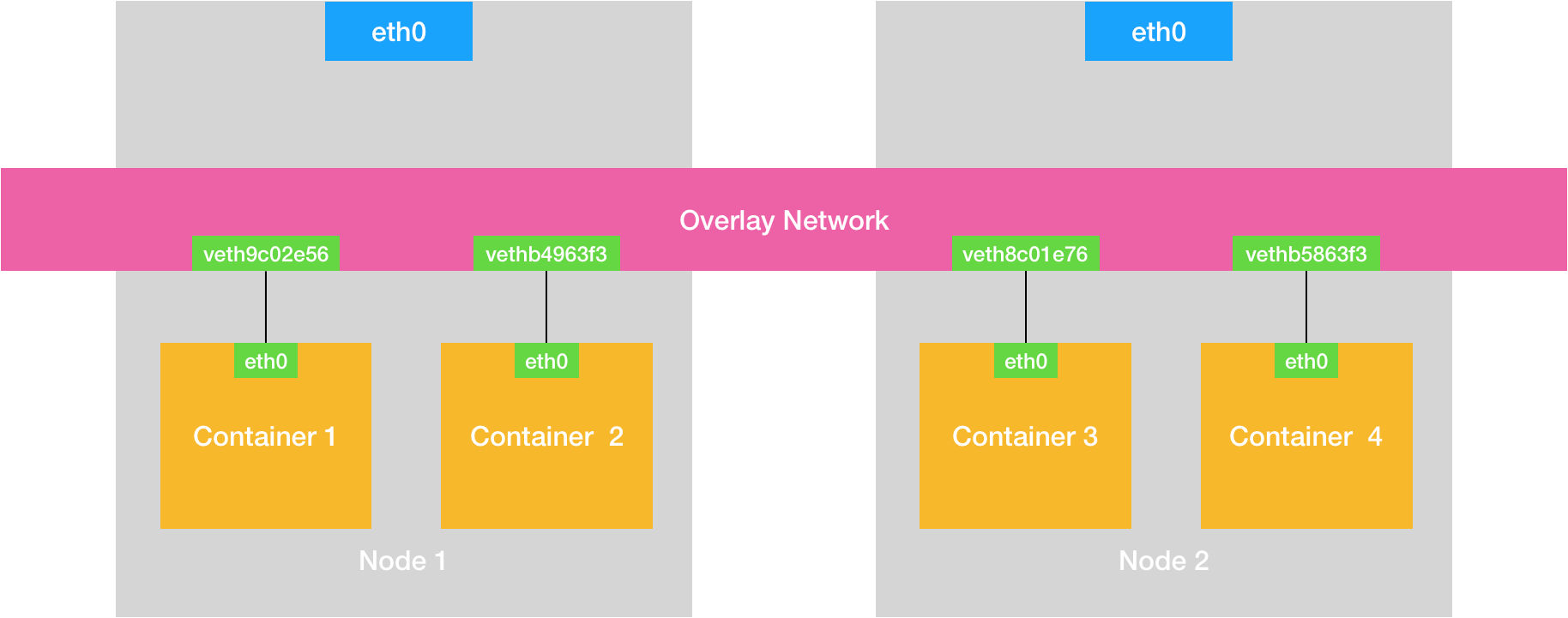
可以看到,构建这种容器网络的核心在于:我们需要在已有的宿主机网络上,再通过软件构建一个覆盖在已有宿主机网络之上的、可以把所有容器连通在一起的虚拟网络。所以,这种技术就被称为:Overlay Network(覆盖网络)。 这是一个概念技术, 下面我们就来看看真正的实体技术了。
容器跨主机网络通信
容器的跨主机交流首先是在
Flannel 项目本身只是一个框架,真正为我们提供容器网络功能的,是 Flannel 的后端实现。目前,Flannel 支持三种后端实现,分别是:
- VXLAN;(目前来说最好的, 可以跨子网)
- host-gw;(缺点是只能在同一子网内的节点之间进行Pod网络通信,不支持跨子网或跨VPC的网络通信。)
- UDP。(性能最差的)
这三种不同的后端实现,正代表了三种容器跨主网络的主流实现方法。
而 UDP 模式,是 Flannel 项目最早支持的一种方式,却也是性能最差的一种方式。所以,这个模式目前已经被弃用。不过,Flannel 之所以最先选择 UDP 模式,就是因为这种模式是最直接、也是最容易理解的容器跨主网络实现。
容器“跨主网络”的实现原理
下面我会来一一介绍一下他们, 但是重点的应该是VXLAN, 因为这个是目前用的 也是最好的, udp虽然已经被剔除了 ,但是他是最初始的, 所以为了便于我们理解整个历程还是来学下的好。 我这里主要是以张磊老师的案例和资料进行学习。
UDP模式
以下面的例子来说
两台宿主机。
- 宿主机 Node 1 上有一个容器 container-1,它的 IP 地址是
100.96.1.2,对应的 docker0 网桥的地址是:100.96.1.1/24。- 宿主机 Node 2 上有一个容器 container-2,它的 IP 地址是
100.96.2.3,对应的 docker0 网桥的地址是:100.96.2.1/24。我们现在的任务,就是让 container-1 访问 container-2。
流程如下:
这种情况下,container-1 容器里的进程发起的 IP 包,其源地址就是 100.96.1.2,目的地址就是 100.96.2.3。由于目的地址 100.96.2.3 并不在 Node 1 的 docker0 网桥的网段里,所以这个 IP 包会被交给默认路由规则,通过容器的网关进入 docker0 网桥(如果是同一台宿主机上的容器间通信,走的是直连规则),从而出现在宿主机上。
这时候,这个 IP 包的下一个目的地,就取决于宿主机上的路由规则了。此时,Flannel 已经在宿主机上创建出了一系列的路由规则。
1 | # 在Node 1上 |
由于我们的 IP 包的目的地址是 100.96.2.3,它匹配不到本机 docker0 网桥对应的 100.96.1.0/24 网段,只能匹配到第二条、也就是 100.96.0.0/16 对应的这条路由规则,从而进入到一个叫作 flannel0 的设备中。
而这个 flannel0 设备的类型就比较有意思了:它是一个 TUN 设备(Tunnel 设备)。
在 Linux 中,TUN 设备是一种工作在三层(Network Layer)的虚拟网络设备。TUN 设备的功能非常简单,即:在操作系统内核和用户应用程序之间传递 IP 包。
flannel的工作方式
以 flannel0 设备为例:
像上面提到的情况,当操作系统将一个 IP 包发送给 flannel0 设备之后,flannel0 就会把这个 IP 包,交给创建这个设备的应用程序,也就是 Flannel 进程。这是一个从内核态(Linux 操作系统)向用户态(Flannel 进程)的流动方向。
反之,如果 Flannel 进程向 flannel0 设备发送了一个 IP 包,那么这个 IP 包就会出现在宿主机网络栈中,然后根据宿主机的路由表进行下一步处理。这是一个从用户态向内核态的流动方向。
所以,当 IP 包从容器经过 docker0 出现在宿主机,然后又根据路由表进入 flannel0 设备后,宿主机上的 flanneld 进程(Flannel 项目在每个宿主机上的主进程),就会收到这个 IP 包。然后,flanneld 看到了这个 IP 包的目的地址,是 100.96.2.3,就把它发送给了 Node 2 宿主机。
Flannel在UDP模式下的工作原理:
- 首先,Flannel在每个主机上运行一个名为flanneld的代理程序。这些代理程序在主机之间相互通信,以协调容器子网的分配和管理。
- 当一个新主机加入集群时,flanneld代理程序会从Etcd(一个分布式键值存储系统)获取一个子网,并将其分配给该主机上的容器。每个主机都会知道其他主机的子网分配信息。
- 当一个容器需要与另一个主机上的容器通信时,主机上的flanneld代理程序会首先检查目标容器的IP地址。如果目标容器位于同一主机上,数据包将直接发送。如果目标容器位于另一个主机上,数据包将被封装在一个UDP数据包中,并通过主机的物理网络发送。
- 接收主机上的flanneld代理程序会解封装UDP数据包,并将原始数据包发送给目标容器。
:::info
详细说下一条数据从进入主机到达到容器的过程
当一个数据包到达主机时,它首先会经过主机的网络堆栈。以下是数据包在到达容器之前的处理过程:
- 数据包首先被主机的网络接口接收。网络接口会根据数据包的目标MAC地址判断是否需要处理该数据包。如果目标MAC地址与主机的网络接口匹配,数据包将继续在主机的网络堆栈中传递。
- 数据包接下来会被主机的防火墙处理。防火墙会根据配置的规则检查数据包的源IP地址、目标IP地址、协议和端口等信息,判断是否允许该数据包通过。如果数据包被允许通过,它将继续在网络堆栈中传递。
- 数据包随后会被路由和转发模块处理。路由模块会根据数据包的目标IP地址和主机的路由表判断数据包应该如何转发。在这个过程中,数据包可能会被转发给flannel进程。
- 如果数据包需要发送给flannel,它会被交给flanneld进程。
- 【集群概念了】flanneld进程会根据数据包的目标IP地址查询Etcd中的子网分配信息,确定目标容器位于哪个主机。然后,flanneld会将数据包封装(例如,使用UDP或VXLAN封装),并通过主机的物理网络发送给目标主机。
- 目标主机上的flanneld进程会接收到封装的数据包,并将其解封装以获取原始数据包。接下来,flanneld会将数据包发送给目标容器的网络接口。
- 数据包最后会进入目标容器的网络堆栈。容器内的防火墙和其他网络组件会根据自己的规则处理数据包,最终将其传递给容器内的应用程序。
:::
在我们的例子中,Node 1 的子网是 100.96.1.0/24,container-1 的 IP 地址是 100.96.1.2。Node 2 的子网是 100.96.2.0/24,container-2 的 IP 地址是 100.96.2.3。
而这些子网与宿主机的对应关系,正是保存在 Etcd 当中,如下所示:
1 | $ etcdctl ls /coreos.com/network/subnets |
所以,flanneld 进程在处理由 flannel0 传入的 IP 包时,就可以根据目的 IP 的地址(比如 100.96.2.3),匹配到对应的子网(比如 100.96.2.0/24),从 Etcd 中找到这个子网对应的宿主机的 IP 地址是 10.168.0.3,如下所示:
1 | etcdctl get /coreos.com/network/subnets/100.96.2.0-24 |
而对于 flanneld 来说,只要 Node 1 和 Node 2 是互通的,那么 flanneld 作为 Node 1 上的一个普通进程,就一定可以通过上述 IP 地址(10.168.0.3)访问到 Node 2,这没有任何问题。
所以说,flanneld 在收到 container-1 发给 container-2 的 IP 包之后,就会把这个 IP 包直接封装在一个 UDP 包里,然后发送给 Node 2。不难理解,这个 UDP 包的源地址,就是 flanneld 所在的 Node 1 的地址,而目的地址,则是 container-2 所在的宿主机 Node 2 的地址。
这个请求得以完成的原因是,每台宿主机上的 flanneld,都监听着一个 8285 端口,所以 flanneld 只要把 UDP 包发往 Node 2 的 8285 端口即可。
通过这样一个普通的、宿主机之间的 UDP 通信,一个 UDP 包就从 Node 1 到达了 Node 2。而 Node 2 上监听 8285 端口的进程也是 flanneld,所以这时候,flanneld 就可以从这个 UDP 包里解析出封装在里面的、container-1 发来的原 IP 包。
而接下来 flanneld 的工作就非常简单了:flanneld 会直接把这个 IP 包发送给它所管理的 TUN 设备,即 flannel0 设备。
Linux 内核网络栈就会负责处理这个 IP 包,具体的处理方法,就是通过本机的路由表来寻找这个 IP 包的下一步流向。
接下来的流程,就是通过上面的容器网络,docker0 网桥会扮演二层交换机的角色,将数据包发送给正确的端口,进而通过 Veth Pair 设备进入到 container-2 的 Network Namespace 里。
而 container-2 返回给 container-1 的数据包,则会经过与上述过程完全相反的路径回到 container-1 中。
为什么UDP 模式性能不好 ?
相比于两台宿主机之间的直接通信,基于 Flannel UDP 模式的容器通信多了一个额外的步骤,即 flanneld 的处理过程。而这个过程,由于使用到了 flannel0 这个 TUN 设备,仅在发出 IP 包的过程中,就需要经过三次用户态与内核态之间的数据拷贝,如下所示: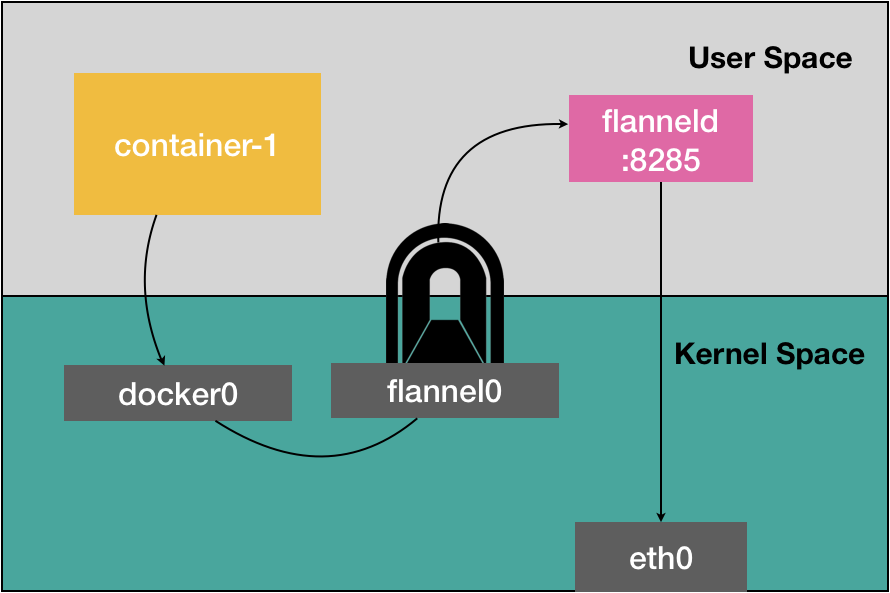
详细流程
- 第一次,用户态的容器进程发出的 IP 包经过 docker0 网桥进入内核态;
- 第二次,IP 包根据路由表进入 TUN(flannel0)设备,从而回到用户态的 flanneld 进程;
- 第三次,flanneld 进行 UDP 封包之后重新进入内核态,将 UDP 包通过宿主机的 eth0 发出去。
此外,我们还可以看到,Flannel 进行 UDP 封装(Encapsulation)和解封装(Decapsulation)的过程,也都是在用户态完成的。在 Linux 操作系统中,上述这些上下文切换和用户态操作的代价其实是比较高的,这也正是造成 Flannel UDP 模式性能不好的主要原因。
所以说,我们在进行系统级编程的时候,有一个非常重要的优化原则,就是要减少用户态到内核态的切换次数,并且把核心的处理逻辑都放在内核态进行。这也是为什么,Flannel 后来支持的 VXLAN 模式,逐渐成为了主流的容器网络方案的原因。
VXLAN 模式主流的容器网络
VXLAN,即 Virtual Extensible LAN(虚拟可扩展局域网),是 Linux 内核本身就支持的一种网络虚似化技术。所以说,VXLAN 可以完全在内核态实现上述封装和解封装的工作,从而通过与前面相似的“隧道”机制,构建出覆盖网络(Overlay Network)。
它的主要设计思想是在现有的物理网络基础上创建虚拟网络,从而实现网络资源的优化和更高的可扩展性。下面来详细学习下。
VXLAN 的覆盖网络的设计思想(理解的重点)
VXLAN 的覆盖网络的设计思想是:在现有的三层网络之上(物理层->数据链路层-> 完网络层, 所以这里说的是网络层的基础上),具体来说,VXLAN通过在原始数据包(如二层数据帧)外封装一个新的IP数据包,创建了一个覆盖网络。这个新的IP数据包包含了VXLAN头部和原始数据包,可以在现有的IP网络上进行传输。当数据包到达目标主机时,会被解封装,恢复成原始的数据帧,然后传递给目标容器。
上面的这个思想会贯穿我们后面所讲解的内容, 所需要不断的结合, 细品。
而为了能够在二层网络上打通“隧道”,VXLAN 会在宿主机上设置一个特殊的网络设备作为“隧道”的两端。这个设备就叫作 VTEP,即:VXLAN Tunnel End Point(虚拟隧道端点)。
** VTEP 设备的作用,其实跟前面的 flanneld 进程非常相似。**
- 只不过,它进行封装和解封装的对象,是二层数据帧(数据链路层);
- 【前面的udp的flannel进程操作的数据包是IP数据包(网络层)】
而且这个工作的执行流程,全部是在内核里完成的(因为 VXLAN 本身就是 Linux 内核中的一个模块)。
上述基于 VTEP 设备进行“隧道”通信的流程
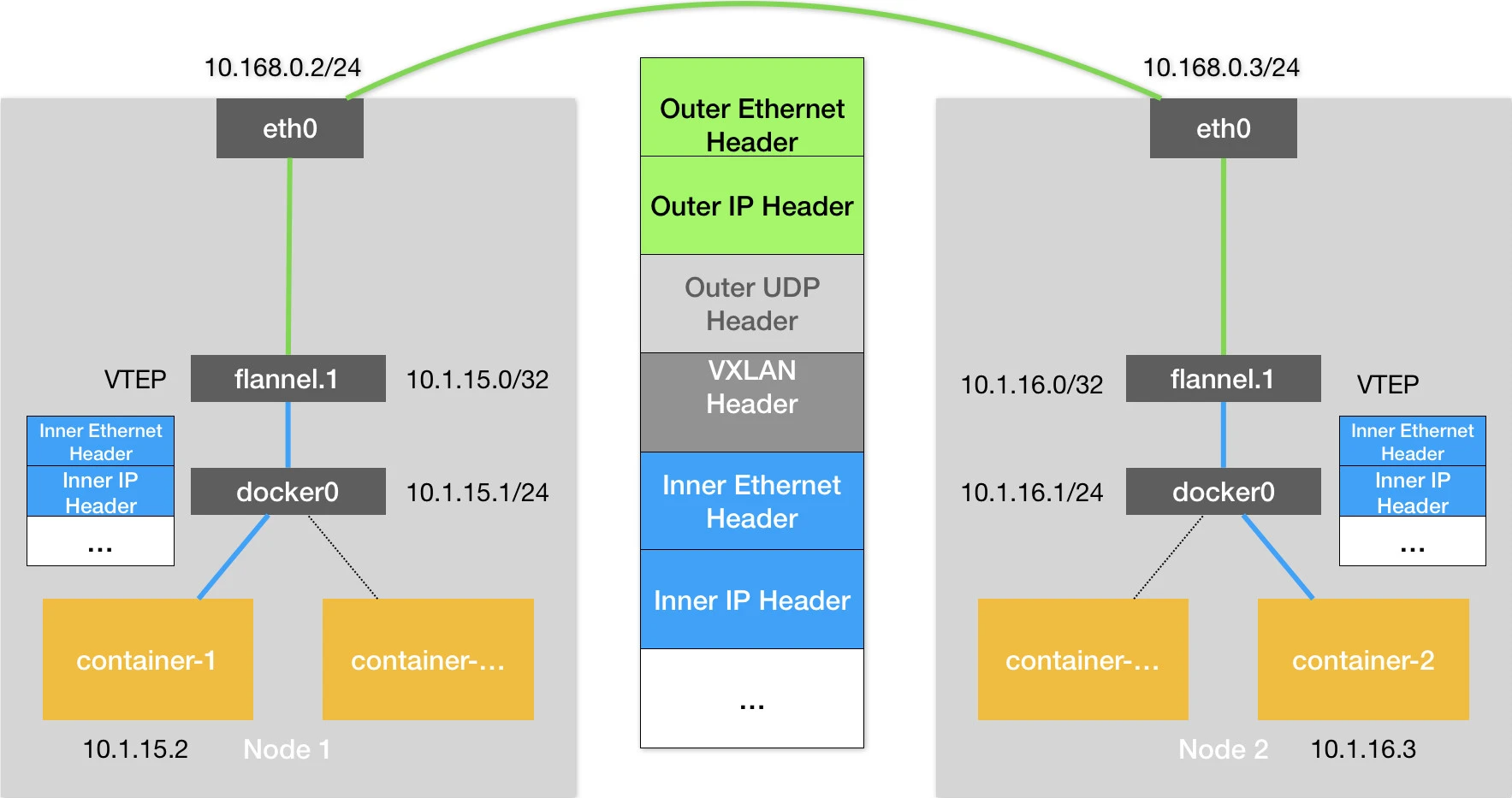
可以看到,图中每台宿主机上名叫 flannel.1 的设备,就是 VXLAN 所需的 VTEP 设备,它既有 IP 地址,也有 MAC 地址。
现在,我们的 container-1 的 IP 地址是 10.1.15.2,要访问的 container-2 的 IP 地址是 10.1.16.3。
那么,与前面 UDP 模式的流程类似,当 container-1 发出请求之后,这个目的地址是 10.1.16.3 的 IP 包,会先出现在 docker0 网桥,然后被路由到本机 flannel.1 设备进行处理。
【不同点】来到了“隧道”的入口。为了方便叙述,我接下来会把这个 IP 包称为“原始 IP 包”。
为了能够将“原始 IP 包”封装并且发送到正确的宿主机,VXLAN 就需要找到这条“隧道”的出口,即:目的宿主机的 VTEP 设备。
而这个设备的信息,正是每台宿主机上的 flanneld 进程负责维护的。
比如,当 Node 2 启动并加入 Flannel 网络之后,在 Node 1(以及所有其他节点)上,flanneld 就会添加一条如下所示的路由规则:
全都是计网知识。可见基础的重要性
1 | $ route -n |
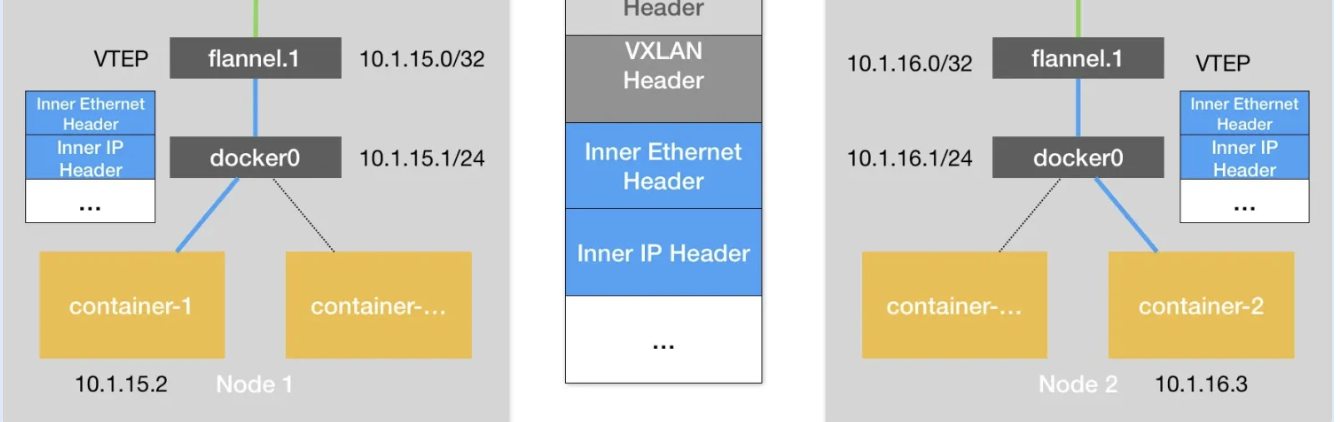
从上面的图片中 Flannel VXLAN 模式的流程图中我们可以看到,10.1.16.0 正是 Node 2 上的 VTEP 设备(也就是 flannel.1 设备)的 IP 地址。
为了方便叙述,接下来我会把 Node 1 和 Node 2 上的 flannel.1 设备分别称为“源 VTEP 设备”和“目的 VTEP 设备”。
而这些 VTEP 设备之间,就需要想办法组成一个虚拟的二层网络,即:通过二层数据帧进行通信。
所以在我们的例子中,“源 VTEP 设备”收到“原始 IP 包”后,就要想办法把“原始 IP 包”加上一个目的 MAC 地址,封装成一个二层数据帧,然后发送给“目的 VTEP 设备”(当然,这么做还是因为这个 IP 包的目的地址不是本机)。
找mac地址 用什么, 当然是APR协议了。 (arp协议怎么找到 自己去学习计算机网络的基础吧, 这里再不能拓展了, 不然就拉不回正题了。)
接下来,Linux 内核还需要再把“内部数据帧”进一步封装成为宿主机网络里的一个普通的数据帧,好让它“载着”“内部数据帧”,通过宿主机的 eth0 网卡进行传输。
为了实现这个“搭便车”的机制,Linux 内核会在“内部数据帧”前面,加上一个特殊的 VXLAN 头,用来表示这个“乘客”实际上是一个 VXLAN 要使用的数据帧。
而这个 VXLAN 头里有一个重要的标志叫作** VNI,它是 VTEP 设备识别某个数据帧是不是应该归自己处理的重要标识。而在 Flannel 中,VNI 的默认值是 1,这也是为何,宿主机上的 VTEP 设备都叫作 flannel.1 的原因**,这里的“1”,其实就是 VNI 的值。
然后,Linux 内核会把这个数据帧封装进一个 UDP 包里发出去。
但是,我们知道,UDP 包是一个四层数据包,所以 Linux 内核会在它前面加上一个 IP 头,即原理图中的 Outer IP Header,组成一个 IP 包。并且,在这个 IP 头里,会填上前面通过 FDB 查询出来的目的主机的 IP 地址,即 Node 2 的 IP 地址 10.168.0.3。
然后,Linux 内核再在这个 IP 包前面加上二层数据帧头,即原理图中的 Outer Ethernet Header,并把 Node 2 的 MAC 地址填进去。这个 MAC 地址本身,是 Node 1 的 ARP 表要学习的内容,无需 Flannel 维护。然后就得到了这样的一数据帧格式
至此**,封包工作就宣告完成了。 **
下面就是拆包工作了
- Node 1 上的 flannel.1 设备就可以把这个数据帧从 Node 1 的 eth0 网卡发出去。显然,这个帧会经过宿主机网络来到 Node 2 的 eth0 网卡。
- Node 2 的内核网络栈会发现这个数据帧里有 VXLAN Header,并且 VNI=1。所以 Linux 内核会对它进行拆包,拿到里面的内部数据帧,然后根据 VNI 的值,把它交给 Node 2 上的 flannel.1 设备。
- 而 flannel.1 设备则会进一步拆包,取出“原始 IP 包”。接下来就回到了我在上一篇文章中分享的单机容器网络的处理流程。最终,IP 包就进入到了 container-2 容器的 Network Namespace 里。**
以上,就是 Flannel VXLAN 模式的具体工作原理了。





