
有状态应用的编排-statefulSet
前置
在学习StatefulSet之前, 我们先看下什么是有状态应用, 什么是无状态应用。
- 有状态应用: 简单来说是指那些需要存储和管理持久化数据的应用
- 无状态应用就是不需要管理存储和持久化数据的应用
之前我们使用的deployment, 他就是管理无状态应用的控制器。 如果想要管理有状态应用, 他是不的 ,为什么呢?
首先, 他的设计初衷就是为了管理无状态应用的, 基本上就没考虑过有状态应用。 如果你读过张磊老师的《深入剖析kubernetes》你就会知道 ,云原生时代刚开始的那几年里, 有状态应用一直是界内“禁忌般”的话题 。
其次, Deplotment更新pod的时候是直接删除旧的, 然后创建新的。 再通过平滑的滚动更新来实现更新操作。 如果出问题 ,那就直接回滚到之前的pod版本。
最后, 对于Deployment来说, 通过ReplicaSet管理副本数量的方式是将多的删除 ,少的创建就行了,并没有考虑创建的顺序、也不需要关心数据一致性等等。这些都说明着deployment不适合管理有状态应用。
管理有状态应用的法宝——StatefulSet
首先, 来介绍一下他把, StatefulSet的设计初衷就是为有状态应用设计的资源类型,它支持有序部署、扩展和回滚。StatefulSet为每个Pod分配一个持久化标识符(如myapp-0、myapp-1等),并确保在更新过程中按照预期的顺序创建和删除Pod。此外,StatefulSet还支持持久化存储,以便Pod在重启或重新调度时保留数据。
适用场景
StatefulSet 对于需要满足以下一个或多个需求的应用程序很有价值:
- 稳定的、唯一的网络标识符。
- 稳定的、持久的存储。
- 有序的、优雅的部署和扩缩。
- 有序的、自动的滚动更新。
限制情况
- 给定 Pod 的存储必须由 PersistentVolume Provisioner (例子在这里) 基于所请求的 storage class 来制备,或者由管理员预先制备。
- 删除或者扩缩 StatefulSet 并不会删除它关联的存储卷。 这样做是为了保证数据安全,它通常比自动清除 StatefulSet 所有相关的资源更有价值。
- StatefulSet 当前需要无头服务(Headless Services)来负责 Pod 的网络标识。你需要负责创建此服务。
- 当删除一个 StatefulSet 时,该 StatefulSet 不提供任何终止 Pod 的保证。 为了实现 StatefulSet 中的 Pod 可以有序且体面地终止,可以在删除之前将 StatefulSet 缩容到 0。
- 在默认 Pod 管理策略(
OrderedReady) 时使用滚动更新, 可能进入需要人工干预才能修复的损坏状态。
StatefulSet的设计思想
StatefulSet是一种高级工作负载资源,专为需要稳定网络标识和稳定持久存储的应用程序而设计。 StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
StatefulSet的设计是将真实世界的应用状态抽象为了两种状态 , 拓展状态和 存储状态。
- 拓扑状态
什么是拓展状态呢 ? 拓展就意味着应用的多个实例之间并不是完全对等的关系。 他们可能是相互依赖的 。比如应用的主节点 A 要先于从节点 B 启动。而如果你把 A 和 B 两个 Pod 删除掉,它们再次被创建出来时也必须严格按照这个顺序才行。并且,新创建出来的 Pod,必须和原来 Pod 的网络标识一样,这样原先的访问者才能使用同样的方法,访问到这个新 Pod。
- 存储状态
应用的多个实例分别绑定了不同的存储数据。对于这些应用实例来说,Pod A 第一次读取到的数据,和隔了十分钟之后再次读取到的数据,应该是同一份,哪怕在此期间 Pod A 被重新创建过。这种情况最典型的例子,就是一个数据库应用的多个存储实例。
所以,StatefulSet 的核心功能,就是通过某种方式记录这些状态,然后在 Pod 被重新创建时,能够为新 Pod 恢复这些状态。
拓展的探究及Service的实践
Service 是 Kubernetes 项目中用来将一组 Pod 暴露给外界访问的一种机制。比如,一个 Deployment 有 3 个 Pod,那么我就可以定义一个 Service。然后,用户只要能访问到这个 Service,它就能访问到某个具体的 Pod。在pod里面再根据负载均衡访问到某个容器 。
这个Service里面的门道可多着呢, 之前在学习iptables和ipvs的时候就是从这里找到的启发。 这里我们先简单介绍一下, 后续在进行详细介绍。
Service 是如何访问到pod的呢?
第一种方式,是以 Service 的 VIP(Virtual IP,即:虚拟 IP)方式。比如:当我访问 10.0.23.1 这个 Service 的 IP 地址时,10.0.23.1 其实就是一个 VIP,它会把请求转发到该 Service 所代理的某一个 Pod 上。(Service为关联的Pod提供负载均衡功能。当外部客户端发送请求到Service的网络端口时,Kubernetes会根据负载均衡策略选择一个Pod来处理请求)这里的具体原理,我会在后续的 Service 章节中进行详细介绍。
第二种方式,就是以 Service 的 DNS 方式。比如:这时候,只要我访问“my-svc.my-namespace.svc.cluster.local”这条 DNS 记录,就可以访问到名叫 my-svc 的 Service 所代理的某一个 Pod。
而在第二种 Service DNS 的方式下,具体还可以分为两种处理方法:
第一种处理方法,是 Normal Service。这种情况下,你访问“my-svc.my-namespace.svc.cluster.local”解析到的,正是 my-svc 这个 Service 的 VIP,后面的流程就跟 VIP 方式一致了。
而第二种处理方法,正是 Headless Service。这种情况下,你访问“my-svc.my-namespace.svc.cluster.local”解析到的,直接就是 my-svc 代理的某一个 Pod 的 IP 地址。可以看到,这里的区别在于,Headless Service 不需要分配一个 VIP,而是可以直接以 DNS 记录的方式解析出被代理 Pod 的 IP 地址。
回到我们之前讨论的问题, service是如何发现pod的?
在之前, 我们是通过创建Service的yaml 然后通过selector下的app标签来指定, 比如这个
1 | apiVersion: v1 |
这个Service就会发现所有的pod名为nginx的。但是可以看到,所谓的 Headless Service,其实仍是一个标准 Service 的 YAML 文件。只不过,它的 clusterIP 字段的值是:None,即:这个 Service,没有一个 VIP 作为“头”。这也就是 Headless 的含义。所以,这个 Service 被创建后并不会被分配一个 VIP,而是会以 DNS 记录的方式暴露出它所代理的 Pod。
然后关键就被引出来了,当你按照这样的方式创建了一个 Headless Service 之后,它所代理的所有 Pod 的 IP 地址,都会被绑定一个这样格式的 DNS 记录,如下所示:
1 | <pod-name>.<svc-name>.<namespace>.svc.cluster.local |
这个 DNS 记录,正是 Kubernetes 项目为 Pod 分配的唯一的“可解析身份”(Resolvable Identity)。
有了这个“可解析身份”,只要你知道了一个 Pod 的名字,以及它对应的 Service 的名字,你就可以非常确定地通过这条 DNS 记录访问到 Pod 的 IP 地址。
1 | apiVersion: apps/v1 |
当这两个 Pod 都进入了 Running 状态之后,你就可以查看到它们各自唯一的“网络身份”了。
我们使用 kubectl exec 命令进入到容器中查看它们的 hostname$ kubectl exec web-0 -- sh -c 'hostname'
得到的内容就是web-1和web-0 。
可以看到,这两个 Pod 的 hostname 与 Pod 名字是一致的,都被分配了对应的编号。接下来,我们再试着以 DNS 的方式,访问一下这个 Headless Service:$ kubectl run -i --tty --image busybox:1.28.4 dns-test --restart=Never --rm /bin/sh
可以看到,当我们把这两个 Pod 删除之后,Kubernetes 会按照原先编号的顺序,创建出了两个新的 Pod。并且,Kubernetes 依然为它们分配了与原来相同的“网络身份”:web-0.nginx 和 web-1.nginx。
然后,在这个 Pod 的容器里面,我们尝试用 nslookup 命令,解析一下 Pod 对应的 Headless Service:nslookup web-0.nginx
规则就是创建通过statefulset控制器的对象名- 对应的pod编号, 然后再.加上service的name
<sts>-<编号>.<service名>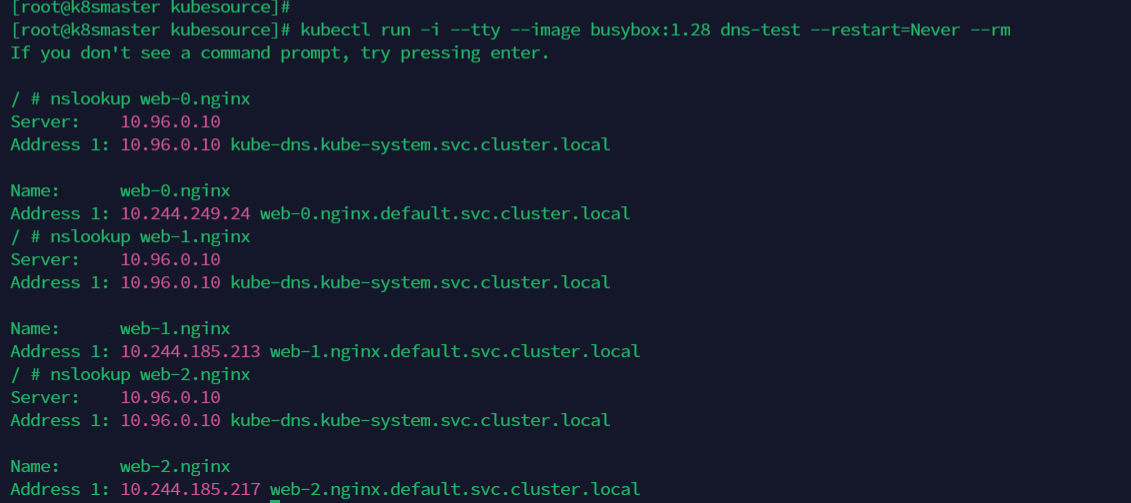
从 nslookup 命令的输出结果中,我们可以看到,在访问 web-0.nginx 的时候,最后解析到的,正是 web-0 这个 Pod 的 IP 地址;而当访问 web-1.nginx 的时候,解析到的则是 web-1 的 IP 地址。
service访问pod的方式来探讨StatefulSet
当我们把这两个 Pod 删除之后,Kubernetes 会按照原先编号的顺序,创建出了两个新的 Pod。并且,Kubernetes 依然为它们分配了与原来相同的“网络身份”:web-0.nginx 和 web-1.nginx。
通过这种严格的对应规则,StatefulSet 就保证了 Pod 网络标识的稳定性。
通过这种方法,Kubernetes 就成功地将 Pod 的拓扑状态(比如:哪个节点先启动,哪个节点后启动),按照 Pod 的“名字 + 编号”的方式固定了下来。此外,Kubernetes 还为每一个 Pod 提供了一个固定并且唯一的访问入口,即:这个 Pod 对应的 DNS 记录。
这些状态,在 StatefulSet 的整个生命周期里都会保持不变,绝不会因为对应 Pod 的删除或者重新创建而失效。
不过,相信你也已经注意到了,尽管 web-0.nginx 这条记录本身不会变,但它解析到的 Pod 的 IP 地址,并不是固定的。这就意味着,对于“有状态应用”实例的访问,你必须使用 DNS 记录或者 hostname 的方式,而绝不应该直接访问这些 Pod 的 IP 地址。
存储状态
存储的管理是一个与计算实例的管理完全不同的问题。** PersistentVolume 子系统为用户和管理员提供了一组 API, 将存储如何制备的细节从其如何被使用中抽象出来。 为了实现这点,我们引入了两个新的 API 资源:PersistentVolume 和 PersistentVolumeClaim。**
下面来解释一下这两个名词
- 持久卷(PersistentVolume,PV) 是集群中的一块存储,可以由管理员事先制备, 或者使用存储类(Storage Class)来动态制备。 持久卷是集群资源,就像节点也是集群资源一样。PV 持久卷和普通的 Volume 一样, 也是使用卷插件来实现的,只是它们拥有独立于任何使用 PV 的 Pod 的生命周期。 此 API 对象中记述了存储的实现细节,无论其背后是 NFS、iSCSI 还是特定于云平台的存储系统。
- 持久卷申领(PersistentVolumeClaim,PVC) 表达的是用户对存储的请求。概念上与 Pod 类似。 Pod 会耗用节点资源,而 PVC 申领会耗用 PV 资源。Pod 可以请求特定数量的资源(CPU 和内存)。同样 PVC 申领也可以请求特定的大小和访问模式 (例如,可以挂载为 ReadWriteOnce、ReadOnlyMany、ReadWriteMany 或 ReadWriteOncePod, 请参阅访问模式)。
最简单的用法
- 声明一个PVC
1 | kind: PersistentVolumeClaim |
可以看到,在这个 PVC 对象里,不需要任何关于 Volume 细节的字段,只有描述性的属性和定义。比如,storage: 1Gi,表示我想要的 Volume 大小至少是 1 GiB;accessModes: ReadWriteOnce,表示这个 Volume 的挂载方式是可读写,并且只能被挂载在一个节点上而非被多个节点共享。
- 在pod中通过pvc使用这个pv
1 | apiVersion: v1 |
可以看到,在这个 Pod 的 Volumes 定义中,我们只需要声明它的类型是 persistentVolumeClaim,然后指定 PVC 的名字,而完全不必关心 Volume 本身的定义。
这时候,只要我们创建这个 PVC 对象,Kubernetes 就会自动为它绑定一个符合条件的 Volume。可是,这些符合条件的 Volume 又是从哪里来的呢?
答案是,它们来自于由运维人员维护的 PV(Persistent Volume)对象。接下来,我们一起看一个常见的 PV 对象的 YAML 文件:
- pv对象
1 | kind: PersistentVolume |
这个 PV 对象的 spec.rbd 字段,正是我们前面介绍过的 Ceph RBD Volume 的详细定义。而且,它还声明了这个 PV 的容量是 10 GiB。这样,Kubernetes 就会为我们刚刚创建的 PVC 对象绑定这个 PV。
所以,Kubernetes 中 PVC 和 PV 的设计,实际上类似于“接口”和“实现”的思想。开发者只要知道并会使用“接口”,即:PVC;而运维人员则负责给“接口”绑定具体的实现,即:PV。
为什么pod重建后数据不会丢失
其实,我和你分析一下 StatefulSet 控制器恢复这个 Pod 的过程,你就可以很容易理解了。
- 首先,当你把一个 Pod,比如 web-0,删除之后,这个 Pod 对应的 PVC 和 PV,并不会被删除,而这个 Volume 里已经写入的数据,也依然会保存在远程存储服务里(比如,我们在这个例子里用到的 Ceph 服务器)。
- 此时,StatefulSet 控制器发现,一个名叫 web-0 的 Pod 消失了。所以,控制器就会重新创建一个新的、名字还是叫作 web-0 的 Pod 来,“纠正”这个不一致的情况。
- 需要注意的是,在这个新的 Pod 对象的定义里,它声明使用的 PVC 的名字,还是叫作:www-web-0。这个 PVC 的定义,还是来自于 PVC 模板(volumeClaimTemplates),这是 StatefulSet 创建 Pod 的标准流程。
- 所以,在这个新的 web-0 Pod 被创建出来之后,Kubernetes 为它查找名叫 www-web-0 的 PVC 时,就会直接找到旧 Pod 遗留下来的同名的 PVC,进而找到跟这个 PVC 绑定在一起的 PV。
这样,新的 Pod 就可以挂载到旧 Pod 对应的那个 Volume,并且获取到保存在 Volume 里的数据。
通过这种方式,Kubernetes 的 StatefulSet 就实现了对应用存储状态的管理。
还有一种理解方式就是
- 首先,StatefulSet 的控制器直接管理的是 Pod。这是因为,StatefulSet 里的不同 Pod 实例,不再像 ReplicaSet 中那样都是完全一样的,而是有了细微区别的。比如,每个 Pod 的 hostname、名字等都是不同的、携带了编号的。而 StatefulSet 区分这些实例的方式,就是通过在 Pod 的名字里加上事先约定好的编号。
- 其次,Kubernetes 通过 Headless Service,为这些有编号的 Pod,在 DNS 服务器中生成带有同样编号的 DNS 记录。只要 StatefulSet 能够保证这些 Pod 名字里的编号不变,那么 Service 里类似于 web-0.nginx.default.svc.cluster.local 这样的 DNS 记录也就不会变,而这条记录解析出来的 Pod 的 IP 地址,则会随着后端 Pod 的删除和再创建而自动更新。这当然是 Service 机制本身的能力,不需要 StatefulSet 操心。
- 最后,StatefulSet 还为每一个 Pod 分配并创建一个同样编号的 PVC。这样,Kubernetes 就可以通过 Persistent Volume 机制为这个 PVC 绑定上对应的 PV,从而保证了每一个 Pod 都拥有一个独立的 Volume。
在这种情况下,即使 Pod 被删除,它所对应的 PVC 和 PV 依然会保留下来。所以当这个 Pod 被重新创建出来之后,Kubernetes 会为它找到同样编号的 PVC,挂载这个 PVC 对应的 Volume,从而获取到以前保存在 Volume 里的数据。
总结
从这些讲述中,我们不难看出 StatefulSet 的设计思想:StatefulSet 其实就是一种特殊的 Deployment,而其独特之处在于,它的每个 Pod 都被编号了。而且,这个编号会体现在 Pod 的名字和 hostname 等标识信息上,这不仅代表了 Pod 的创建顺序,也是 Pod 的重要网络标识(即:在整个集群里唯一的、可被访问的身份)。
有了这个编号后,StatefulSet 就使用 Kubernetes 里的两个标准功能:Headless Service 和 PV/PVC,实现了对 Pod 的拓扑状态和存储状态的维护





