
关系数据理论
问题提出
首先,我们可以知道一个关系模式应当是五元组。
1 | R(U,D,DOM,F) |
因为D、DOM域模式设计关系不大, 因此我们这里暂不考虑
1 | R<U,F> |
作为一个二维表,关系要符合一个最基本的条件 :
每一个分量必须时不可分的数据项,满足这一条件的关系模式就属于第一范式
数据依赖:
一个关系内部属性与属性之间的一种约束关系。
有许多数据依赖 :最重要的就是函数依赖 和 多值依赖
1 | 格式 : |
关系模式图:
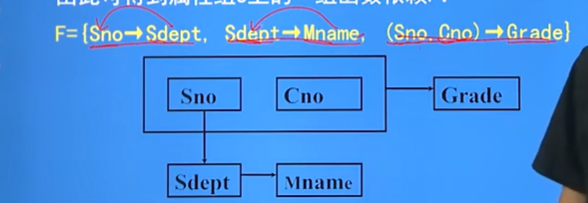
该关系模式会出现的问题
- 数据冗余
- 更新异常
- 插入异常
- 删除异常
一个好的模式应当不会发生插入异常,删除异常,更新异常,数据冗余也要仅可能的少。
规范化
函数依赖
设R(U)是属性集U上的关系模式, X、Y是U的子集。(也就是说X、Y是Sno、Sname两个属性,U是这个属性组)
1 | X函数确定Y 或者 说Y函数依赖于X |
- 非平凡的函数依赖
1 | X -> Y 但是y不属于x, 则称为X-> Y 是非平凡的函数依赖 |
- 平凡的函数依赖
1 | X -> Y y属于x, 则称为X-> Y 是平凡的函数依赖 |
- 完全函数依赖
1 | 在R(U), 如果X-> Y ,并且对于x的任何一个真子集X`, 都有X` 不能推出 Y |
也就说
(Sno, Cno)-->Grade : 想要得出Grade ,那么就必须知道Sno和Cno , 缺一不可
- 部分函数依赖
1 | 若X-> Y, 但是Y不完全依赖于X,则称Y对X部分函数依赖。 |
也就说
(Sno, Cno)-->Cno : 想要得出Cno ,那么只需要知道Sno和Cno 其中的一个即可
- 传递函数依赖
1 | 在R(U)中,如果X->Y , Y-/->X, Y->Z, Z不属于Y,则成为Z对X传递函数依赖 |
码
也就是我们平时所学的键, 只是叫法不同
1 | 设K为R<U,F>中得属性 或者属性组合, 若 K -F-> U,则K为R得候补码 |
包含在任何一个候补码中的属性被称为主属性, 反之,不包含在任何一个候补码中的属性被称为非主属性 / 非码属性。
最简单的情况下,单个属性是码, 最极端情况下,整个属性组都是码。称为全码
范式
范式也就相当于是规则。
关系型数据库中的关系要满足一定的要求, 满足不同程度的要求的为不同范式。
1 | 第一范式 : 1NF |
2NF
若 R ∈ 1NF ,并且每个非主属性完全函数依赖于任何一个候选码, 则R ∈ 2NF .
比如 :
1 | (Sno , Cno ) -F-> Grade # 非主属性 Grade 完全依赖于Sno 和 Cno |
如果说一个关系模型不满足 2NF,那么他就会出现以下几个问题 。
- 修改复杂
- 插入异常
- 删除异常
3NF
设关系模式 R<U,F> ∈1NF, 如不存在这样的码 X ,属性组 Y 及给主属性Z(Z !∈ Y )使得 X-> Y,Y->Z成立。则称R<U,F> ∈3NF
1 | 简单来说。 |
BCNF
设关系模式 R<U,F> ∈1NF 若 X->Y 且 Y !∈ X时, X必含有码。则称R<U,F> ∈BCNF
重点 : X必含有码
由上述BCNF的定义我们可以知道, 满足BCNF的关系依赖 。就必须要有
1 | - 所有的非主属性对每个码都是完全函数依赖 |
对于后续的多值依赖 与 4NF等等, 这里不做讲解。依次类推
**RANK()用法 : **
在数据库中,RANK() 是一个窗口函数,它为结果集中的每一行分配一个唯一的排名值。RANK() 函数根据指定的排序顺序对行进行排序,并为具有相同排序值的行分配相同的排名。在这种情况下,下一个排名值将是连续的整数序列中的下一个值。通常,RANK() 函数与 OVER() 子句一起使用,以指定排序依据的列。
以下是一个简单的例子,假设我们有一个名为 sales 的表,其中包含 salesperson 和 sales_amount 两个列。我们想要按销售额为销售人员排名:
1 | SELECT salesperson, sales_amount, |
在这个查询中,RANK() 函数根据 sales_amount 列的降序值为每个销售人员分配一个排名。OVER() 子句定义了排序依据的列。
如果你想根据分组为每个销售人员分配排名,可以使用 PARTITION BY 子句。例如,假设 sales 表还包含一个名为 region 的列,你可以按地区对销售人员进行排名:
1 | SELECT region, salesperson, sales_amount, |
在这个查询中,我们首先根据 region 列将销售人员分组,然后在每个分组内按 sales_amount 列的降序值为销售人员分配排名。PARTITION BY 子句允许我们在每个分组内重新开始排名。





