
数据库对象
常见的数据库对象
- 表 : 存储数据的逻辑单元
- 数据字典 : 就是系统表, 存放数据库相关的信息
- 约束 : 执行数据校验的规则,用于保证数据完整性的规则
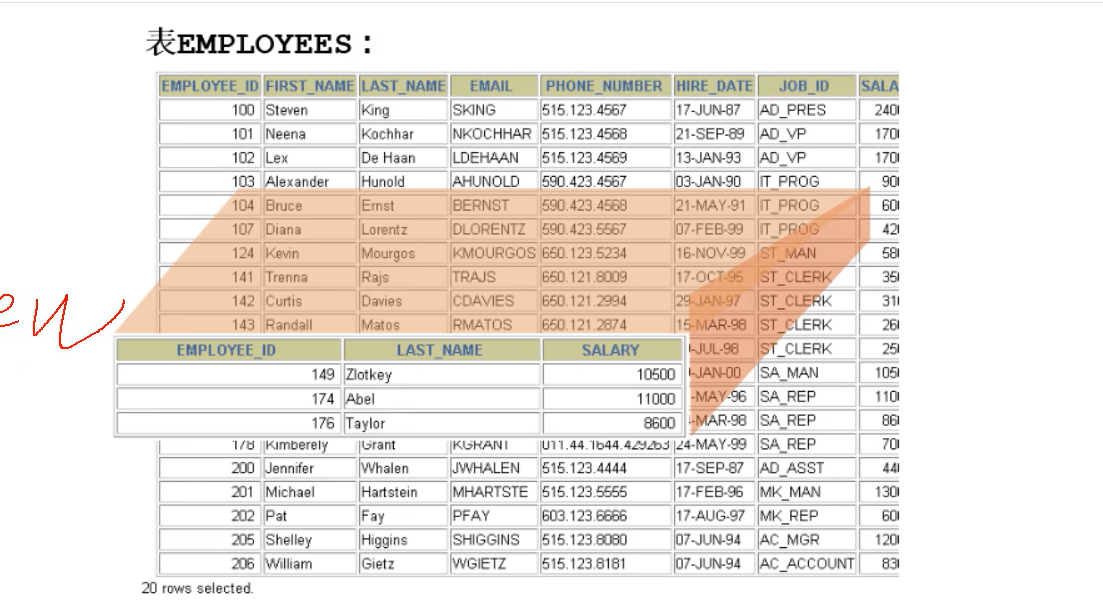
- 视图 :一个或者多个数据表里的数据的逻辑显示,试图并不存储数据
- 索引 :用于提高查询性能,相当于书的索引
- 存储过程 : 用于完成一次完整的业务处理,没有返回值,但是可通过传出参数将多个值传给调用环境
- 存储函数 : 用于完成一次特定的计算,具有返回值
- 触发器 : 相当于一个时间监听器,当数据库发生特定时间后,触发器被触发,完成响应的处理
视图概述
他就相当于一种存储起来的select语句
1 | 一个或者多个数据表里的数据的逻辑显示,并无法真正的处理数据 |
对视图进行CRUD操作,也就是对数据库中的对应的表进行操作。因为数据只有一份,试图就是他的一种显示形式
试图本省的删除,不会导致对基表中数据的删除。
1 | 视图不仅可以创建在一个表或者多个基本表上, |
为什么使用视图(优点)
- 控制数据访问权限,对相关保密的内容不给相关的人员查询到。
- 简化查询
- 减少数据冗余
- 数据安全操作
- 适应灵活多变的需求
- 能够分解复杂的查询逻辑
为什么不使用视图(缺点)
- 基于表,所以需要及时进行维护(维护成本高)
基本使用
**语法: **
1 | CREATE VIEW 视图名[(对应的字段列表)] |
删除视图:
1 | DROP VIEW 视图名; |
更新视图:
1 | 更新视图 就是指通过视图来插入、删除和修改数据 |
**修改视图: **
1 | 由于基表中某些字段发生改变,所以我们的视图需要进行对应的修改 |
视图更新失败的原因
- 视图由两个以上的基本表导出,不能更新
- 视图中的字段来自于函数、表达式、常量等 或者说字段本身不存在的情况,就会更新失败
- 若视图中含有GROUP BY 子句,不能更新
- 视图定义中含有DISTINCT短语,不能更新
- 视图定义中有嵌套查询等
- ….
存储过程与存储函数
**概念: **
1 | - 存储过程 : **用于完成一次完整的业务处理**,没有返回值,但是可通过传出参数将多个值传给调用环境 |
理解
含义 :
存储过程 :就是一组经过预先编译的SQL语句的封装。
1 | 执行过程: |
**好处 : **
- 简化操作,提高SQL语句的重要性,减少开发程序员的压力
- 减少操作过程中的失误,提高效率
- 减少网络传输量
- 减少SQL语句暴露在网络上的风险,提高安全性
和视图的对比
1 | - 视图时虚拟表 |
语法
**分类 : **
- 没有参数(无参无返回)
- 仅仅带有IN类型(有参无返回)
- 仅仅带有OUT类型(无参有返回)
- 即带有IN 又带有OUT (有参有返回)
1 | CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型) ----如果不写, 默认为IN |
特征
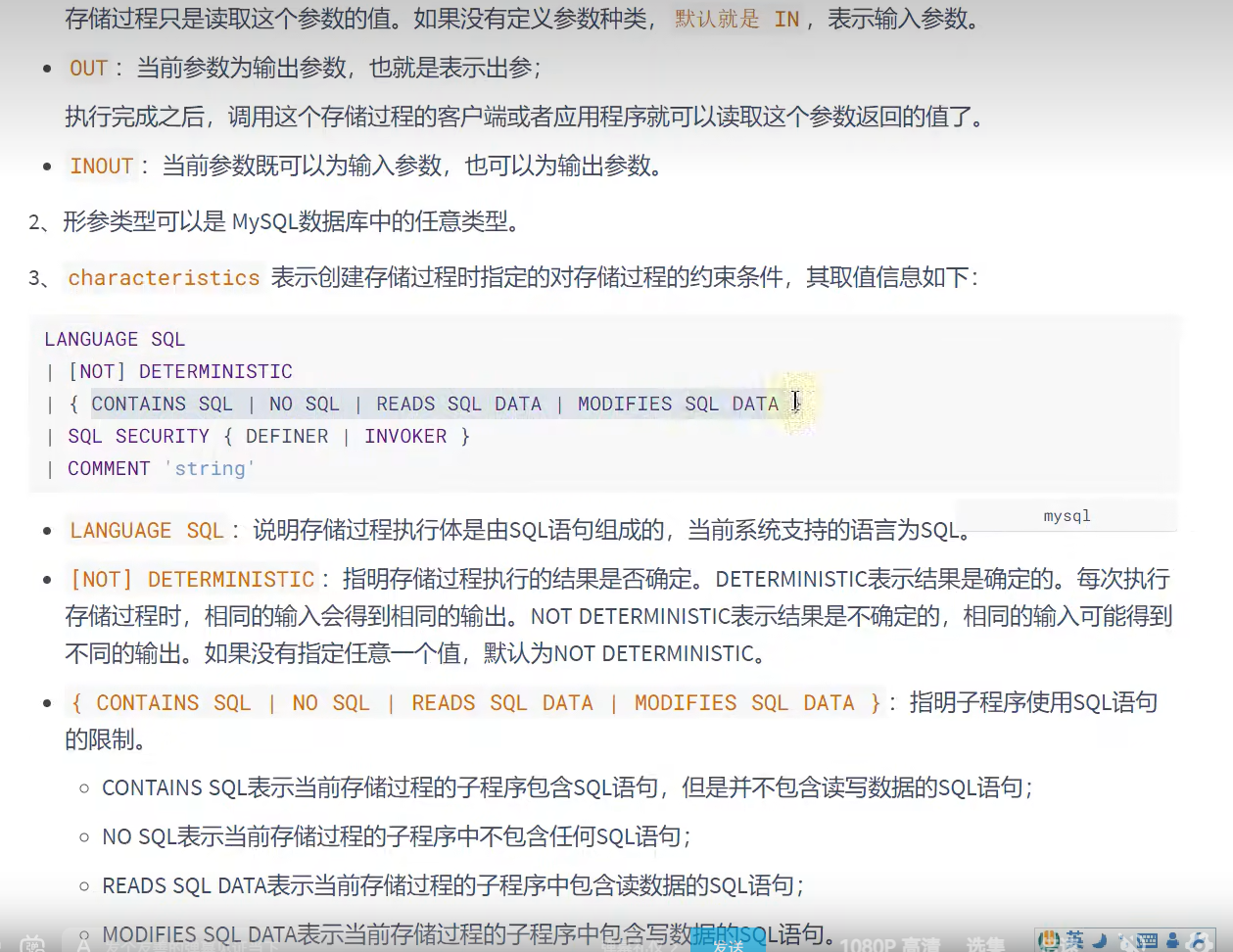
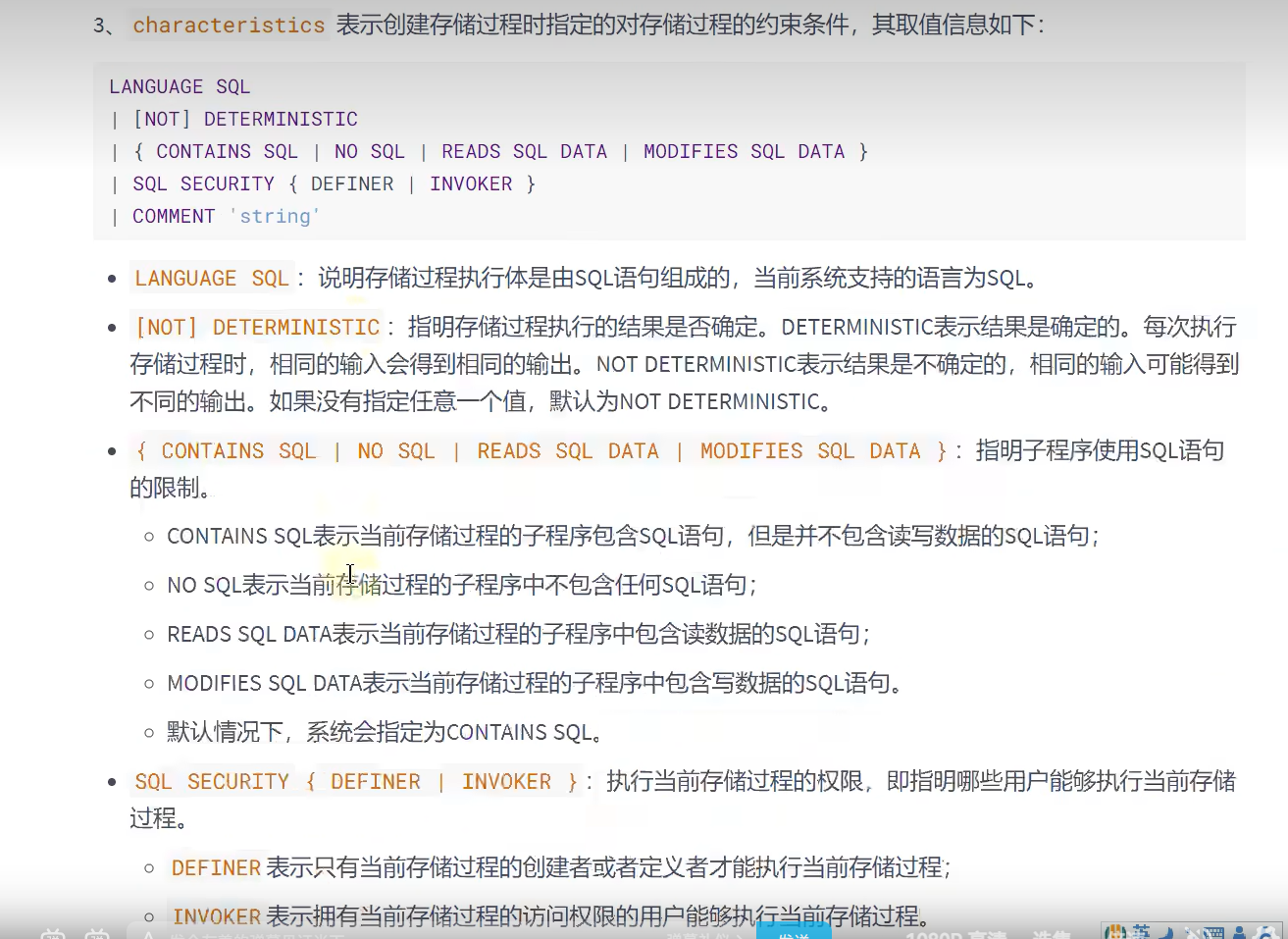

对比两者 :

数据库完整性
实体完整性
实体完整性就是说 : 创建表的时候用PRIMARY KEY 来定义单属性
对单属性构成有两种说明方法:
- 列级约束
1 | CREATE TABLE student( |
- 表级约束
1 | CREATE TABLE student( |
对于多个属性构成的码(键),只有一种说明方法,即定义为表级约束条件
1 | CREATE TABLE student( |
对于实体完整性的检查,我们要做的就是如果不符合就禁止操作。(add or update)
参照完整性
参照完整性(referential integrity)定义 :
是关系型数据库的一个概念,它用于确保在两个表之间的关联关系中,引用的外键值必须存在于被引用的主键表中。
也就是说,如果一个表中的某个字段(外键)引用了另一个表中的一个字段(主键),那么这个外键值必须存在于被引用的主键表中,否则就会违反参照完整性。
1 | CREATE TABLE `student1` ( |
当不符合参照完整性时, 我们可以采取以下操作来进行修改
- 拒绝执行
- 级联操作
- 设置为空值
用户完整性
简单的说, 用户完整性就是对表中的字段的限制条件。
比如说我们的主键不能为空,所以我们会通过使用NOT NULL的方式来设置, 如果说其他字段,比如学号 它具有唯一性, 所以我们可以通过使用UNIQUE来进行设置。
官方解释:
1 | 是指在关系型数据库中,除了参照完整性以外,用户还可以通过定义规则或限制来保证数据的完整性和一致性。这些规则或限制是由用户或应用程序开发人员定义的,用于限制数据的输入或修改,从而确保数据的正确性和可靠性。 |
属性上的约束具体由三种
列值非空(
NOT NULL)列值唯一(
UNIQUE)检查列值是否满足某一条件表达式(
CHECK短语)
1 | CREATE TABLE student( |
断言
官方解释
1 | 在关系型数据库中,断言(assertion)是一种用于检查数据库中数据是否符合特定条件的逻辑表达式。它与数据检查约束类似,但更加灵活和通用。与数据检查约束只能限制某个字段的取值范围或格式不同,断言可以涵盖整个表或多个表之间的数据关系,并且可以执行更为复杂的逻辑判断。 |
举例来说
就是我们的学生-课程表 ,每个课程最多只能有60 个人,如果大于60 那么剩余的就会添加失败。(限制数据库表的数量)
- 添加断言格式
1 | create assertion 断言名 |
- 删除断言格式
1 | DROP ASSERTION 断言名; |
触发器
官方解释:
1 | 触发器(Trigger)是一种数据库对象,用于在特定的数据库操作(如INSERT、UPDATE或DELETE操作)执行之前或之后自动执行一些指定的动作。触发器通常用于实现数据完整性约束和业务逻辑,以及在数据发生变化时执行一些自定义的操作。 |
触发器又叫事件-条件-动作规则
- 创建触发器 :
1 | CREATE TRIGGER trigger_name |
其中,定义触发器的关键字包括:
CREATE TRIGGER:创建一个新的触发器对象。trigger_name:触发器的名称,应该唯一且易于识别。{BEFORE | AFTER}:指定触发器在相应的数据库操作之前或之后执行。{INSERT | UPDATE | DELETE}:指定触发器要响应的事件类型。ON table_name:指定触发器要关联的表名。[FOR EACH ROW]:指定触发器的执行方式,对于每一行数据是否执行一次。[WHEN condition]:指定触发器执行的条件,如果条件不满足,则触发器不会执行。BEGIN...END:触发器执行的动作,可以包含一条或多条SQL语句或存储过程。
例如,以下是一个在表employees上创建一个在INSERT操作之前触发的触发器的示例:
1 | CREATE TRIGGER before_insert_employee -- 创建触发器 |
- 激活触发器 :
1 | 触发器的执行是由出发事件激活的,并由数据库服务器自动执行的。 |





