
Kubernetes安装总结
主要步骤
- 准备一台虚拟机k8s-centos7(2c4g),安装通用环境:CentOS docker kubelet kubeadm kubectl chrony
- 通过k8s-centos7克隆三台虚拟机:k8smaster、k8snode1、k8snode2
- 在k8smaster节点执行kubeadm init命令初始化集群
- 配置CNI网络插件
- 在k8snode1和k8snode2节点上执行 kubeadm join命令,把节点添加到当前集群
- 通过部署nginx进行测试
:::info
注意
如果kubernetes出现故障需要重新安装的, 需要先执行kubeadm reset 然后才能init
:::
基础的配置(虚拟机为例)
基础步骤
1、在VMware中新建虚拟机k8s-master(2c4g),安装CentOS 7
2、在VMware中输入root用户名和密码登录CentOS,修改网卡配置文件
cd /etc/sysconfig/network-scripts/
vi ifcfg-ens33
需要修改的内容如下(IP地址第3个数字以本机VMware配置为准)
1 | BOOTPROTO="static" |
保存退出后,重启网卡:systemctl restart network
通过ping命令检查网络是否连通
ping www.baidu.com
3、用Xterm连接k8s-centos7,后续操作都在Xterm中完成
4、更新系统,关闭防火墙等 然后更新系统
yum update -y
5、 重启
reboot
6、 永久关闭防火墙
systemctl disable firewalld
7、 永久关闭selinux
sed -i ‘s/enforcing/disabled/‘ /etc/selinux/config
8、 永久关闭swap分区
sed -ri ‘s/.swap./#&/‘ /etc/fstab
9、 重启
reboot
剩下Docker的安装不做赘述
然后就是配置时间节点
master节点
1)修改配置文件 vi /etc/chrony.conf
a、找到 Allow NTP client access from local network,
取消下一行注释即可,即:allow 192.168.0.0/16
b、找到 Serve time even if not synchronized to a time source.
取消下一行注释即可,即:local stratum 10
2)重启服务端chrony服务,systemctl restart chronyd.service
2个node节点
1)配置文件修改 vi /etc/chrony.conf
修改server,删掉其它的server配置
添加要同步时间的源服务器ip
格式为:server 192.168.43.163 iburst
2)重启客户端chrony服务,systemctl restart chronyd.service
3)chronyc sources -v 完成同步
kubernetes集群
初始化集群
上面的步骤基本上网上都有, 从下面开始就是真正进入到了kubernetes的配置了。 这里我需要提醒的是, 遇到报错先看报错信息, 看自己能不能理解, 如果能理解了再试着解决, 而不是将问答cy到浏览器上然后拉到最底下看解决方案, 这样学不到东西的。
回归正题, 初始化集群步骤
- 首先看是否关闭了swap分区
free -m
为什么需要关闭swap分区?
我刚开始也是不理解, 搜就行。
Kubernetes 对 swap 分区的使用有一定的限制
- 首先是性能会受到影响, 我们都知道, 应用上云的作用就是为了提效提能。 但是swap是为了缓存内存和处理器而存在的, 这就相当于多了一步处理, 所以kubernetes需要关闭它
- 稳定性的考虑 , Kubernetes 的某些组件(如 kubelet)可能会遇到稳定性问题,当系统内存紧张时,操作系统会将部分内存页面交换到磁盘上的 swap 分区。这可能导致内存泄漏和其他不稳定问题。
差不多, 我就知道这两点, 当然还有更多的需要我们自己去探索。
- 检查我们的kubernetes的配置文件是否齐全
kubeadm config images list --kubernetes-version=v1.22.12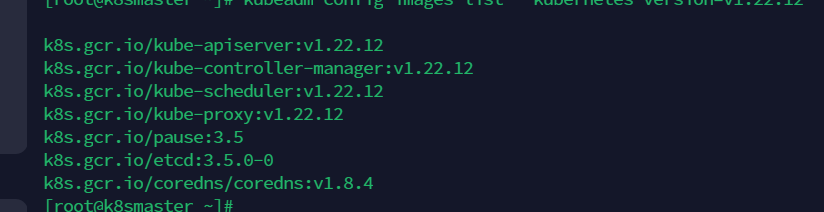
就像我自己的时这个版本的, 具体master需要什么组件, 可以直接去官网看看架构图, 然后再对比一下 。
- 初始化
1 | kubeadm init \ |
注意这里的address 是自己本机的ip , 不知道的用
ip addr查。 然后就是对应的版本好, 自己需要搞清楚, image镜像,cidr指定服务 CIDR(无类别域间路由)范围。pod-cidr指定 Pod CIDR(无类别域间路由)范围
初始化完了之后会有这样一段命令生成. 复制下来
1 | 参考内容如下(已本机信息为准): |
- 集群的管理员配置
1 | mkdir -p $HOME/.kube |
给当前用户创建config , 给与器admin的权限
注意, 这里如果想给其他的pod节点赋予管理员权限, 可以将master节点下的
/etc/kubernetes/admin.conf复制到工作节点的相同目录下。
- 配置CNI网络插件
自己从网上找对应的插件ymal文件吧。 然后apply部署上去就可以用了。
1 | kubectl apply -f calico.yaml |
配置工作节点
分别在k8snode1和k8snode2节点上执行 kubeadm join命令
从master节点安装信息中复制(上面提到了哈)
1 | 参考内容如下(已本机信息为准): |
- 回到master节点检查效果
1 | # 执行: kubectl get nodes |
完成了上述的步骤, 那么你的kubernetes配置就告一段落了, 对于kubeadm、kubelet、kubectl 。 这三者的作用可以网上查,了解个大概,不需要细究,因为可能也理解不清楚。我个人建议, 先实践 然后结合实践在进行理解, 最后自己总结.
部署服务
简单的以nginx为例吧。
我将介绍两种部署方式, 一种是以原生的pod的yaml文件创建。 另一种是通过Deployment创建pod 或者 pods(n个pod) 。
Deployment的作用自己可以查, 后期我也会继续总结。
原生pod的方式
- 创建的yaml文件
这是最简单的一种, 如果想要自己定制化创建, 那么就需要理解每个yaml中的内容, 具体的参数内容解释可以去网上搜, 我这里贴一个别人的https://blog.csdn.net/erhaiou2008/article/details/121857233
1 | apiVersion: v1 |
- 执行创建命令
kubectl apply -f nginx.yaml
然后我们就可以看到状态
这种是他还在创建中, 下面这这种就是创建成功了。
当然,具体的创建过程细节, 和pod的生命周期等等, 我后面都会一一罗列出来。
- 创建到这个 , 你的pod是创建成功了, 但是你想访问却是不行的 。因为你这个pod没有创建对应的Service, 什么是Service? 下面我简要概述一下 ,然后再给你说说怎么创建。
:::info
什么是Service ? Service和pod的关系?
大家在学习kubernetes之前肯定是学习过Docker的, 既然知道Docker, 我们就知道创建了镜像 ,但是不运行你肯定是无法访问的。 Service在这里的作用类似 ,但是绝不相同哈。 我只是给个引导
- 首先, Service是什么 ? ?
Kubernetes Service 是一种抽象概念,用于将一组提供相同功能的 Pods 暴露为一个网络服务 。 这是官方给的定义 ,简单来说他的作用就是提供网络服务的, 让其他人能够访问到我这个服务, 但是他的作用还有很多的。 比如负载均衡、服务发现、访问控制…. 很多, 需要了解自己查, 我这里暂不做引导深入。
- 其次, 我们要知道Serivce怎么为自己创建的pod提供网络服务 ?
这里往深了讲能讲很多 ,我这里不做深入引导, 后续再发文章
- 从简单的yaml文件层面可以看到,在创建Service的yaml文件的时候有个字段叫
Selector它是在spec - selector下的 。- Service 使用
selector部分的标签选择器找到匹配的 Pod。在这里,selector: app: nginx将会选择所有具有app=nginx标签的 Pod。 - 因为我创建的pod的yaml文件中,
nginx-pod定义中包含app: nginx标签,所以该 Pod 会被nginx-serviceService 选中。
- Service 使用
- 所以根据上面的对应关系, Service就会发现我这个pod,如何发现?
当 Service 被创建时,Kubernetes 会根据标签选择器找到匹配的 Pod,并将这些 Pod 的 IP 和端口信息注册到一个 Endpoints 对象中。
这就是我创建的nginx-service和pod的对应关系。 我这个nginx-service网络服务, 执行内部节点的80端口。
然后就进行流量的转发。 转发的规则我们在Service里面也有写 就是targetPort这个字段 。 Service 的spec.ports部分定义了服务的端口(port)和目标端口(targetPort)。 Service 监听集群内的 80 端口 (port: 80),并将流量转发到后端 Pod 的 80 端口 (targetPort: 80)。
当其他 Pod 或服务访问nginx-service的 ClusterIP 地址和 80 端口时,流量会被 kube-proxy 转发到nginx-pod的 80 端口。

- 最后我要讲的是Service的dns解析
Kubernetes DNS 服务会为
nginx-service创建一个 DNS 条目。集群中的任何 Pod 都可以通过nginx-service这个名称解析到 Service 的 ClusterIP 地址。
例如,集群中的其他 Pod 可以通过http://nginx-service访问nginx-pod这个pod。
:::
1 | apiVersion: v1 |
通过上面的分析, 我详细读者会对这个Service如何提供网络服务给到pod有了一知半解,接下来想要验证上面我说的对不对, 可以先看下pod和service
通过kubectl get pods, service
可以看到我们port被转发到了指定的30007端口,接下来 通过节点ip + 映射端口 , 就可以访问到我们的pod服务了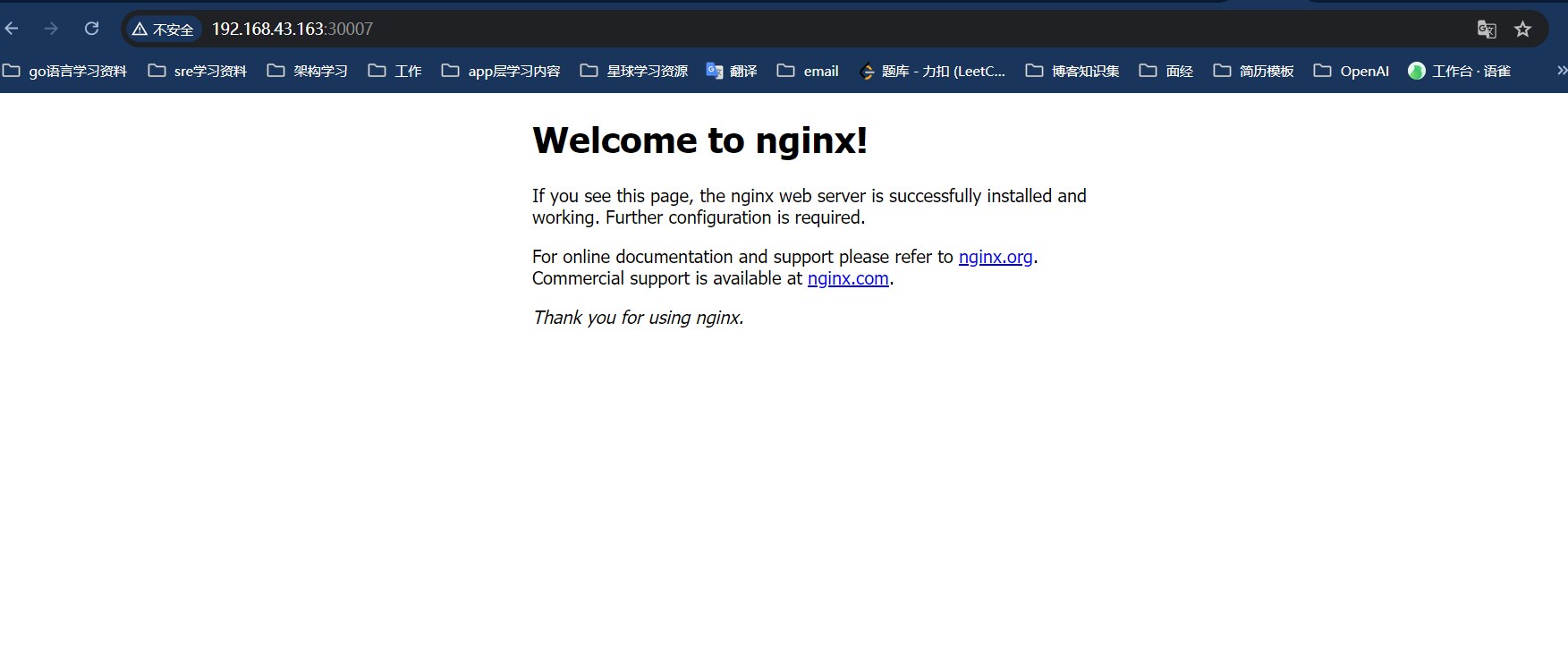
大家可能有疑问, 为什么是通过节点ip 而不是 上面Service提供的cluster-ip?
这里我们提供的Service类型是 NodePort, 就是NodePort Service 将 Service 暴露在每个节点上的一个静态端口,使得外部流量可以通过节点的 IP 和该端口访问服务。
他是根据这个规则来的, 还有 LoadBalancer 或者等。
但是这个cluster-ip为什么不能用呢? 因为 它只能在 Kubernetes 集群内部访问,而不能从集群外部访问 。
好了, 从pod原生的方式部署的服务,相信大家有了一定的了解, 接下来我会解释如何更高效的部署服务、管理pod ,这就用到了Deployment了。
Deployment部署服务
deployment完美的诠释了kubernetes和Docker的区别, 也很好的证明了kubernetes的特点:**容器编排**
具体什么是容器编排呢?
容器编排是指在多个主机上自动部署、管理、扩展和网络容器的过程
首先, 还是给出yaml文件。 我们知道kubernetes部署文件都是通过yaml文件来进行的,所以编写yaml文件, 理解其中的字段是必须要掌握的。
1 | apiVersion: apps/v1 |
看下我们这个pod的yaml文件和上面的有什么区别?
1 | apiVersion: v1 |
1 | apiVersion: apps/v1 |
对比了就不用我多解释了吧。 直白点就是Kind的区别。
Deployment它提供了一套模板, pod的模板, 作用就是为了我们更好的管理pod。
1 | - replicas: 3 # 他的作用就是指定创建的副本数量,如果那天某一个pod挂了, 他就会立马创建一个新的。总之pod总数为3 |
总结
通过上面的配置 + 部署 nginx服务的方式, 相信读者应该能够明白kubernetes部署服务的基本步骤了 。 但是如果想要在现网环境中部署, 那么这点储备是远远不够的。
后续我会详细的介绍部署当中的每个步骤 ,以及对应的原理和拓展内容。




