set
set之所以没有放到和Collection接口一块学习是因为set接口底层实现的还是Map接口。他只是相当于在map接口上做了一次封装。
set接口常用的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public interface Set<E> extends Collection<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean retainAll(Collection<?> c);
boolean removeAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT);
}
}
|
特征:
不能存放重复的元素- **
存放数据是无序的 **(即添加和取出的顺序是不同的,虽然取出的顺序不一致,但是不会一直变)
- set接口对象不能通过索引来获取
HashSet
hashSet底层hashMap
而hashMap的底层其实是数组 + 链表 + 红黑树
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
|
底层如何实现: hash() + equals()
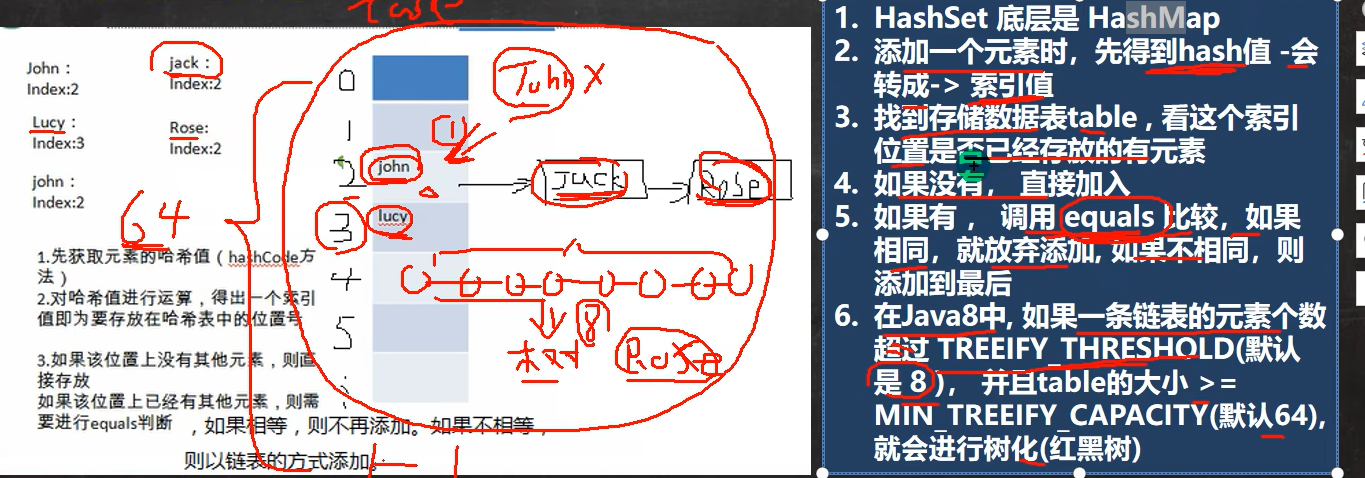
- 先获取元素的hash值
- 对hash值进行运算,得出一个索引值(就是存放在哈希表的位置号)
- 如果该位置上没有其他元素,则直接存入,如果有,那么就需要进行hash比较(调用equals方法) 不同就添加在该位置上元素的后面。相同则添加失败
Hash中添加元素重点★★★★★
- 调用add

- 进入put方法。 key就是传入的值。value就是上面的PRESENT【它的作用就是一个静态的常量】
1
2
|
private static final Object PRESENT = new Object();
|

- 进入hash(key)方法 ,得到hash值

无符号右移16位。源码详情
1
2
3
4
5
6
7
8
|
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
|
执行putVal方法【重点】★★★★★
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
|
扩容机制
hashSet的扩容机制
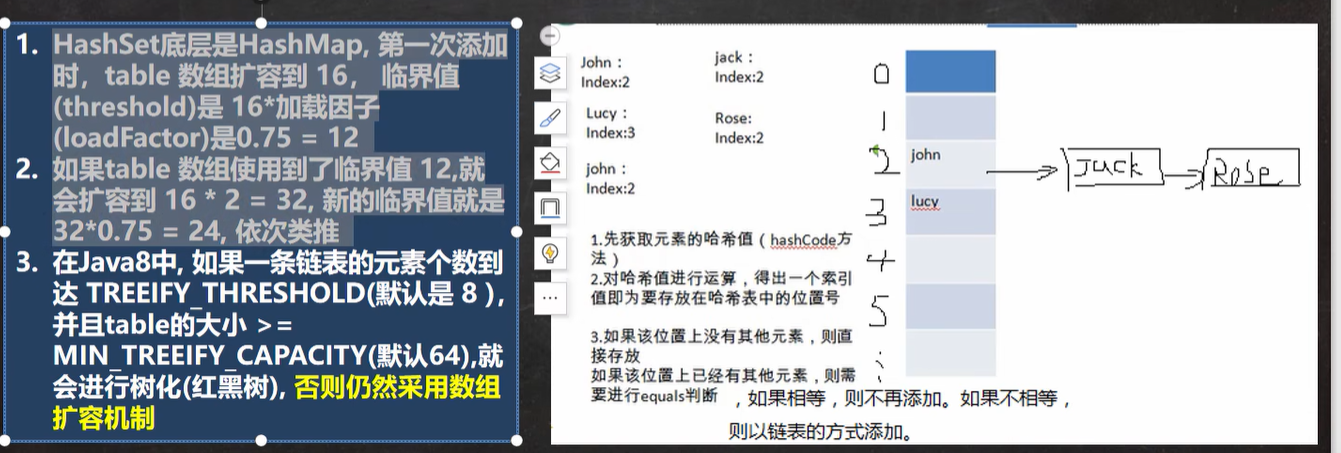
- 首次扩容为 16 临界值(threshold) 是16 * 加载因子 也就是 0.75 = 12
- 如果table数组用到了临界值12 ,那么就会扩容到16 * 2 = 32, 与此同时,新的临界值就是 32 * 0.75 = 24以此类推
- 如果一个链表的个数到达 8 个及以上, 并且数组table的大小 >= 64 ,那么就会进行树化(红黑树!)否则任然采用数组扩容机制
- 对于java8来说,和java7之前的有所不同的是,他是先进行添加(如果达到阙值,比如:第一次添加为12),那么就是先将需要添加的元素进行添加,然后再进行扩容。
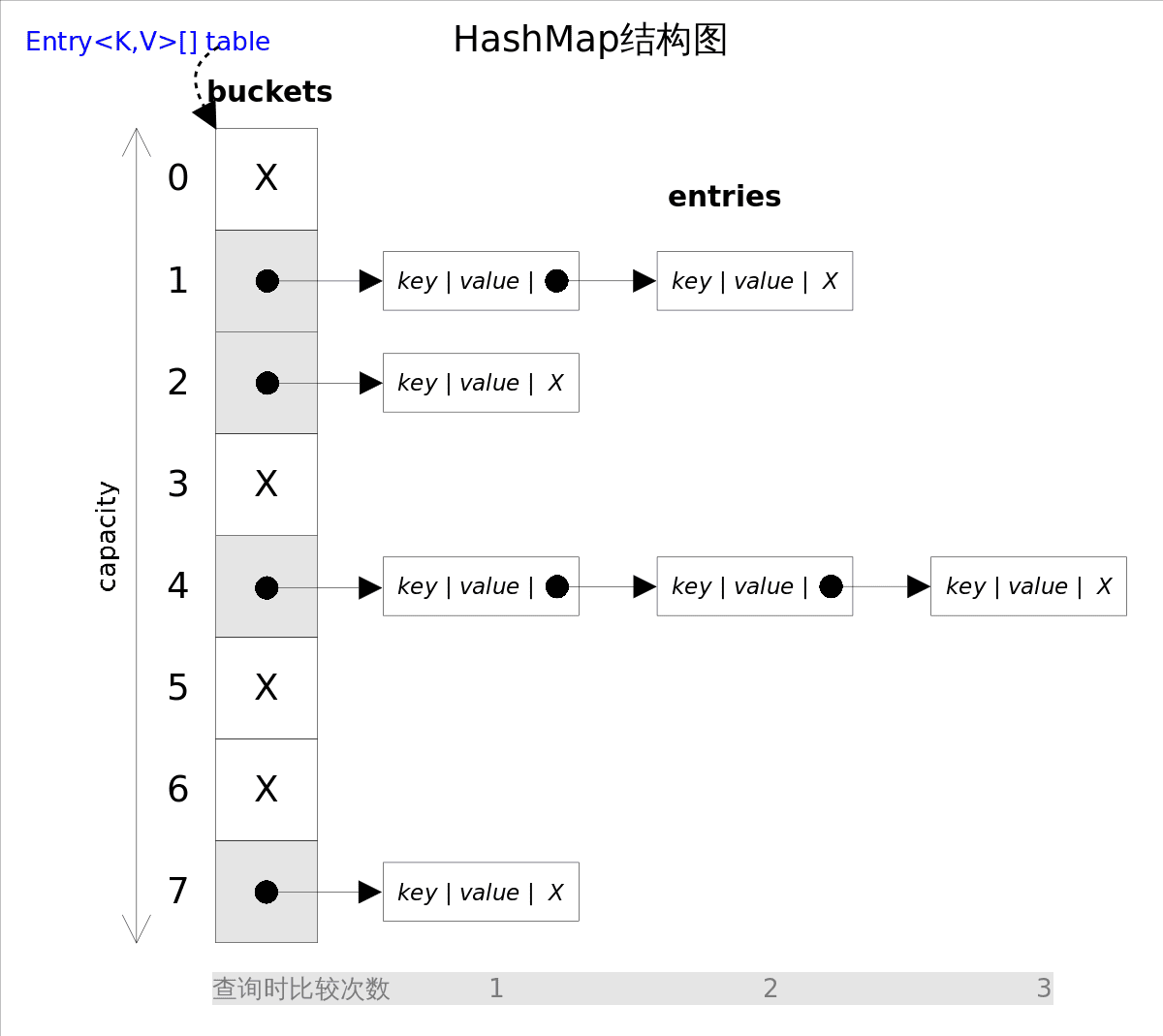
影响hashSet的性能
影响HashMap的性能: 初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。
hashCode()和equals():
hashCode()方法决定了对象会被放到哪个bucket里,当多个对象的哈希值冲突时,equals()方法决定了这些对象是否是“同一个对象”。
所以,如果要将自定义的对象放入到HashMap或HashSet中,需要**@Override** hashCode()和equals()方法。
HashMap中的get方法
hashSet中的获取元素是通过迭代器来实现,但是迭代器也是通过hashMap实现
首先直接调用HashMap的keySet()方法获得一个Set对象,该Set对象的实际类型是KeySet对象
接着再调用KeySet对象的iterator()方法,该方法会返回一个KeyIterator对象
最后向调用者返回迭代器对象
get() 方法是根据指定的key返回value, 对于hash来说,虽然他底层实现是通过hashMap来实现的,但是它却不是继承HashMap 。而是Collection接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
|
该方法调用了getEntry(Object key)得到相应的entry,然后返回entry.getValue()。因此getEntry()是算法的核心。 算法思想是首先通过hash()函数得到对应bucket的下标,然后依次遍历冲突链表,通过key.equals(k)方法来判断是否是要找的那个entry。
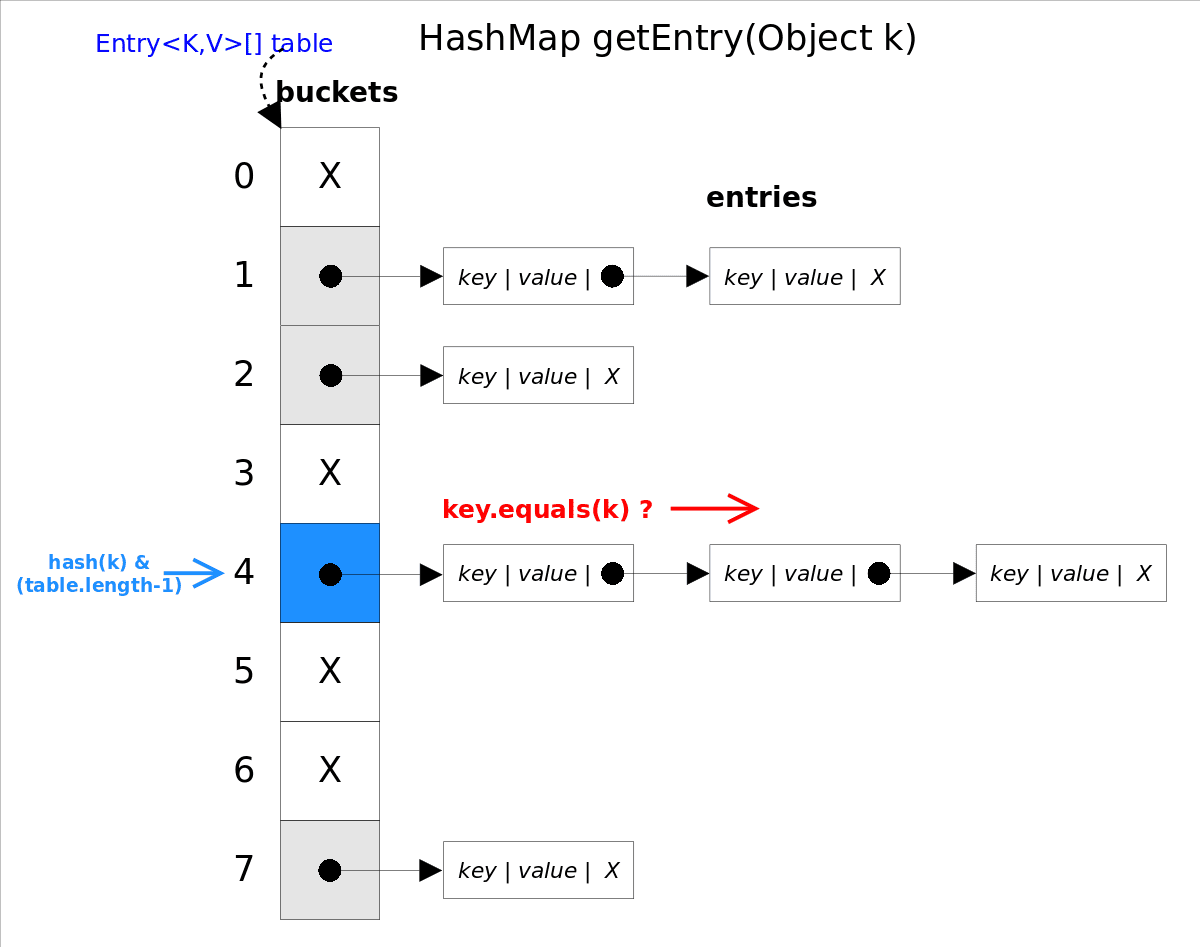
上图中hash(k)&(table.length-1)等价于hash(k)%table.length,原因是HashMap要求table.length必须是2的指数,因此table.length-1就是二进制低位全是1,跟hash(k)相与会将哈希值的高位全抹掉,剩下的就是余数了
HashSet子类—-LinkedHashSet
同时实现set接口
- 底层是LinkedhashMap,维护的是数组 + 双向链表
- 不允许添加重复的元素
- 使用hashCode来决定元素的存储位置。同时使用链表又使得位置连续
- 添加的元素是有序的(双向链表!)
构造器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
|
put
对于添加元素 和之前的相差不大,只是在加入节点时有下列的修改
- 先求hash值,再求索引
- 确定元素在hashTable(hash表)的位置。然后将元素加入双向链表中。
- 需要将pre 和 next 都进行赋值
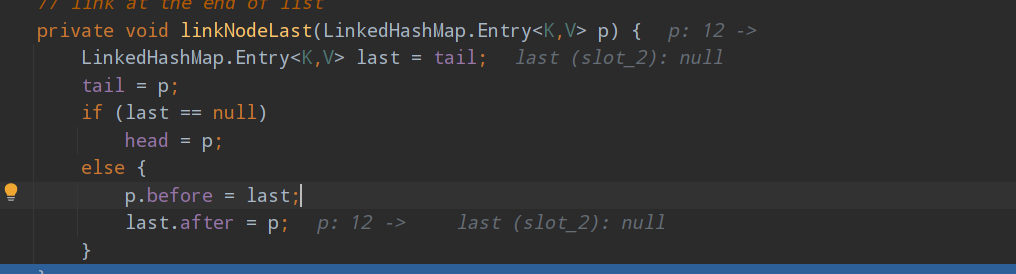
遍历得到元素
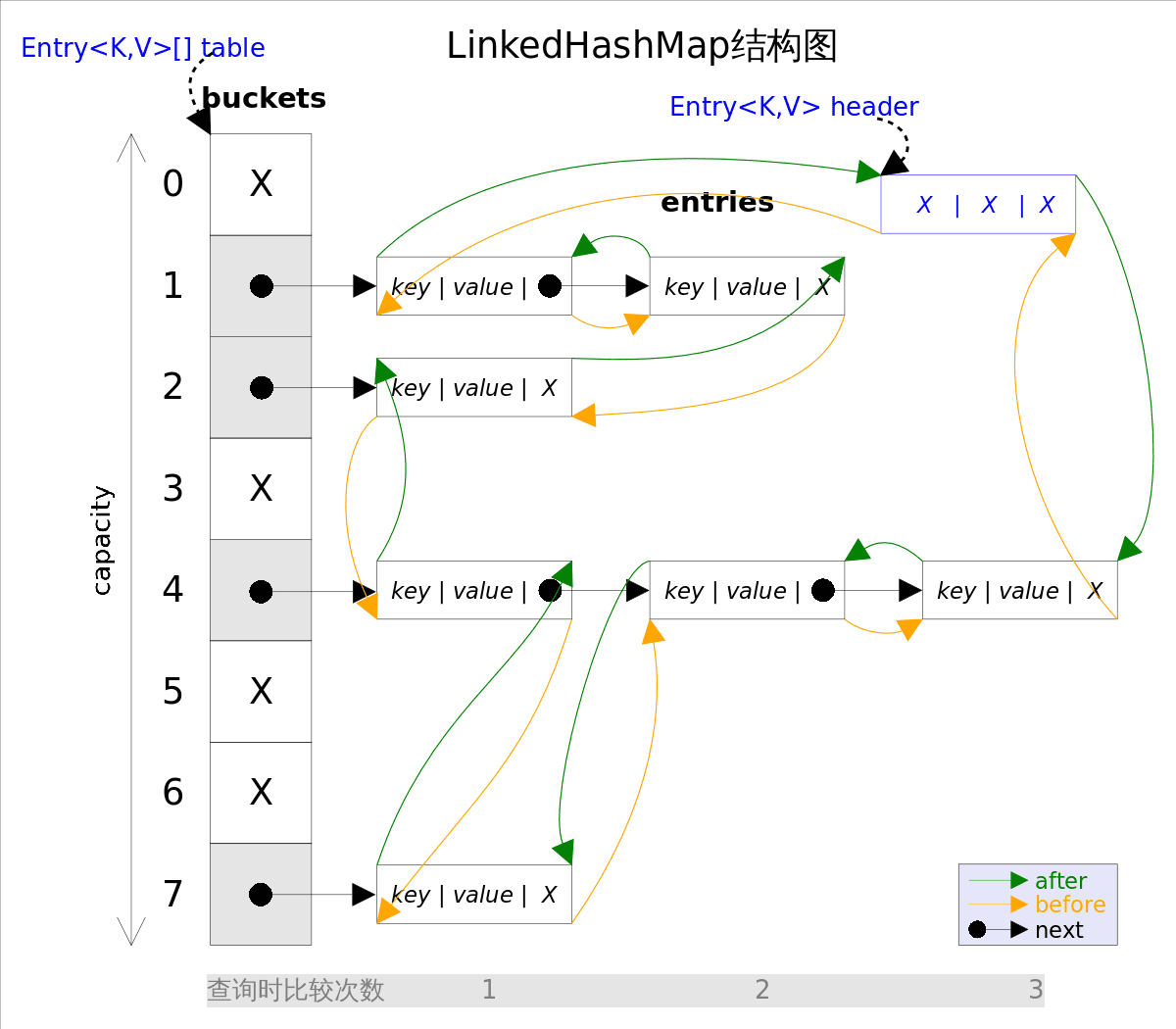
事实上LinkedHashMap是HashMap的直接子类,二者唯一的区别是*LinkedHashMap*在*HashMap*的基础上,采用双向链表(doubly-linked list)的形式将所有entry连接起来,这样是为保证元素的迭代顺序跟插入顺序相同。上图给出了LinkedHashMap的结构图,主体部分跟HashMap完全一样,多了header指向双向链表的头部(是一个哑元),该双向链表的迭代顺序就是entry的插入顺序。
除了可以保迭代历顺序,这种结构还有一个好处 :
迭代LinkedHashMap时不需要像HashMap那样遍历整个table,而只需要直接遍历header指向的双向链表即可,也就是说LinkedHashMap的迭代时间就只跟entry的个数相关,而跟table的大小无关。
TreeSet






