
Python基础回顾
Python数据类型
基本数据类型
多个变量赋值
Python允许你同时为多个变量赋值。例如:
1 | a = b = c = 1 |
以上实例,创建一个整型对象,值为1,三个变量被分配到相同的内存空间上。
您也可以为多个对象指定多个变量。例如:
1 | a, b, c = 1, 2, "john" |
以上实例,两个整型对象 1 和 2 分别分配给变量 a 和 b,字符串对象 “john” 分配给变量 c。
基本数据类型
- int(有符号整型)
- long(长整型,也可以代表八进制和十六进制)
- float(浮点型)
- complex(复数)
布尔类型
和Java中的Boolean相似, 所以基本用法也都相同。
1 | a = True |
标准数据类型
在内存中存储的数据可以有多种类型。
例如,一个人的年龄可以用数字来存储,他的名字可以用字符来存储。
Python 定义了一些标准类型,用于存储各种类型的数据。
Python有五个标准的数据类型:
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
案例回顾
下面是每种数据类型的基本使用和案例说明:
- 数字类型(Numbers)—–可变
数字类型包括整型(int)、浮点型(float)和复数型(complex)。可以进行常见的数学运算,如加减乘除、幂运算、取模运算等。例如:
1 | a = 5 |
- 字符串类型(String) —–不可变
字符串是一系列字符的序列,可以用单引号或双引号括起来。可以进行字符串拼接、切片、大小写转换等操作。例如:
1 | str1 = 'hello' |
- 列表类型(List)
列表是一种有序的集合,可以包含任意类型的元素。可以进行索引、切片、增删改查等操作。例如
1 | lst = [1, 'hello', 2.5, True] |
- 元组(Tuple)—–不可变
元组是一种有序的集合,与列表类似,**但是元组是不可变的,**即元素的值不能修改。可以进行索引、切片等操作。
1 | tup = (1, 'hello', 2.5, True) |
- 集合类型—–元素不重复 , 和set集合类似—–不可变
集合是一种无序的不重复元素的集合,可以进行交并补等操作。
1 | set1 = {1, 2, 3, 4} |
- 字典类型
字典是一种无序的键值对集合,可以根据键来访问值。可以进行增删改查等操作。例如:
1 | dict1 = {'name': 'Tom', 'age': 20, 'gender': 'male'} |
五大数据类型的高级用法
列表类型 (list[] )
内置函数:
| 序号 | 函数 |
|---|---|
| 1 | cmp(list1, list2) 比较两个列表的元素 |
| 2 | len(list) 列表元素个数 |
| 3 | max(list) 返回列表元素最大值 |
| 4 | min(list) 返回列表元素最小值 |
| 5 | list(seq) 将元组转换为列表 |
Python包含以下方法:
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | [list.pop(index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False) 对原列表进行排序 |
set集合类型
集合的创建
1 | # 集合的创建 |
集合的添加元素
1 | # |
集合的删除元素
可以使用remove()或discard()方法删除集合中的一个元素,如果元素不存在,则抛出KeyError异常(remove()方法)或不进行任何操作(discard()方法)。
1 | set1 = {1, 2, 3} |
集合的运算
可以使用union()、intersection()、difference()、symmetric_difference()等方法进行集合的并、交、差、对称差等运算。
1 | set1 = {1, 2, 3} |
判断集合之间的关系
可以使用issubset()、issuperset()、isdisjoint()等方法判断集合之间的包含关系。
1 | set1 = {1, 2, 3} |
数字类型
这个就是相当于将简单的数字类型进行了封装, 如果没有了float 和 double之间的区别
数学函数运算
其中python提供了许多数学函数,可以对数字进行各种运算和计算。常用的数学函数包括abs()、round()、min()、max()、pow()等。
1 | x = -2.5 |
类型转换
1 | x = 2.5 |
元组类型
创建元组()
1 | tuple1 = tuple() |
元组的访问
就是简单的遍历
1 | print(tuple1[0]) # 输出1,第一个元素 |
运算符
可以使用加号+和乘号*来进行元组的拼接和复制操作。
1 | tuple1 = (1, 2, 3) |
- 元素统计
可以使用count()方法统计元素在元组中出现的次数,使用index()方法查找元素在元组中的位置。
1 | tuple1 = (1, 2, 3, 2) |
这些方法可以帮助开发者方便地进行元组的操作和处理。由于元组是不可变的,因此在使用元组时需要注意不能对元素进行修改。
元组内置函数
Python元组包含了以下内置函数
| 序号 | 方法及描述 |
|---|---|
| 1 | cmp(tuple1, tuple2) 比较两个元组元素。 |
| 2 | len(tuple) 计算元组元素个数。 |
| 3 | max(tuple) 返回元组中元素最大值。 |
| 4 | min(tuple) 返回元组中元素最小值。 |
| 5 | tuple(seq) 将列表转换为元组。 |
字符串类型
字符串切片
可以使用切片操作来截取字符串的一部分。切片操作的语法为:s[start:end:step],其中start为起始位置(默认为0),end为结束位置(默认为字符串长度),step为步长(默认为1)。
1 | s = 'Hello, world!' |
字符串拼接
可以使用加号+来进行字符串的拼接操作。
1 | s1 = 'Hello' |
字符串查找
可以使用find()、index()、count()等方法来查找字符串中的子串。
1 | s = 'Hello, world!' |
字符串替换
可以使用replace()方法来替换字符串中的子串。
1 | s = 'Hello, world!' |
字符串分割和连接
可以使用split()方法将字符串按照指定的分隔符进行分割,使用join()方法将字符串列表或元组连接成一个字符串。
1 | s = 'Hello, world!' |
这些方法可以帮助开发者方便地进行字符串的操作和处理。由于字符串是不可变的,因此在使用字符串时需要注意不能对字符串进行修改。
内置函数
| 方法 | 描述 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| string.decode(encoding=’UTF-8’, errors=’strict’) | 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 ‘ignore’ 或 者’replace’ |
| string.encode(encoding=’UTF-8’, errors=’strict’) | 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| string.expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
| string.find(str, beg=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在 string中会报一个异常. |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回 False. |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| string.isnumeric() | 如果 string 中只包含数字字符,则返回 True,否则返回 False |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回 False. |
| string.istitle() | 如果 string 是标题化的(见 title())则返回 True,否则返回 False |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.lower() | 转换 string 中所有大写字符为小写. |
| string.lstrip() | 截掉 string 左边的空格 |
| string.maketrans(intab, outtab) | maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| string.partition(str) | 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
| string.rfind(str, beg=0,end=len(string) ) | 类似于 find() 函数,返回字符串最后一次出现的位置,如果没有匹配项则返回 -1。 |
| string.rindex( str, beg=0,end=len(string)) | 类似于 index(),不过是返回最后一个匹配到的子字符串的索引号。 |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.rpartition(str) | 类似于 partition()函数,不过是从右边开始查找 |
| string.rstrip() | 删除 string 字符串末尾的空格. |
| string.split(str=””, num=string.count(str)) | 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+1 个子字符串 |
| [string.splitlines(keepends]) | 按照行(‘\r’, ‘\r\n’, ‘\n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
| [string.strip(obj]) | 在 string 上执行 lstrip()和 rstrip() |
| string.swapcase() | 翻转 string 中的大小写 |
| string.title() | 返回”标题化”的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| string.translate(str, del=””) | 根据 str 给出的表(包含 256 个字符)转换 string 的字符,要过滤掉的字符放到 del 参数中 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.zfill(width) | 返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
字典类型
创建字典
可以使用花括号{}或dict()方法创建一个字典:
1 | dict1 = {'name': 'Tom', 'age': 20} |
访问字典元素
可以使用键来访问字典中的值,如果键不存在,则会抛出KeyError异常。也可以使用get()方法来访问字典中的值,如果键不存在,则返回指定的默认值。
1 | dict1 = {'name': 'Tom', 'age': 20} |
修改字典元素
可以使用赋值语句对字典中的元素进行修改,如果键不存在,则会添加新的键值对。
1 | dict1 = {'name': 'Tom', 'age': 20} |
删除字典元素
可以使用del语句或pop()方法删除字典中的元素,如果键不存在,则会抛出KeyError异常(del语句)或返回指定的默认值(pop()方法)。
1 | dict1 = {'name': 'Tom', 'age': 20} |
字典视图
字典视图(dictionary view)是一个动态的“窗口”,可以看到字典中的键和值。Python提供了三种字典视图:keys()方法返回字典中的键视图,values()方法返回字典中的值视图,items()方法返回字典中的键值对视图
1 | dict1 = {'name': 'Tom', 'age': 20} |
这些方法可以帮助开发者方便地进行字典的操作和处理。由于字典是无序的,因此在使用字典时需要注意不能依赖字典中元素的顺序。
内置函数:
| 序号 | 函数及描述 |
|---|---|
| 1 | cmp(dict1, dict2) 比较两个字典元素。 |
| 2 | len(dict) 计算字典元素个数,即键的总数。 |
| 3 | str(dict) 输出字典可打印的字符串表示。 |
| 4 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | [dict.fromkeys(seq, val]) 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
| 5 | dict.has_key(key) 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | dict.keys() 以列表返回一个字典所有的键 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 以列表返回字典中的所有值 |
| 11 | [pop(key,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 返回并删除字典中的最后一对键和值 |
字符串的相关内置函数
| 方法 | 描述 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| string.decode(encoding=’UTF-8’, errors=’strict’) | 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 ‘ignore’ 或 者’replace’ |
| string.encode(encoding=’UTF-8’, errors=’strict’) | 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| string.expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
| string.find(str, beg=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在 string中会报一个异常. |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回 False. |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| string.isnumeric() | 如果 string 中只包含数字字符,则返回 True,否则返回 False |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回 False. |
| string.istitle() | 如果 string 是标题化的(见 title())则返回 True,否则返回 False |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.lower() | 转换 string 中所有大写字符为小写. |
| string.lstrip() | 截掉 string 左边的空格 |
| string.maketrans(intab, outtab) | maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| string.partition(str) | 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
| string.rfind(str, beg=0,end=len(string) ) | 类似于 find() 函数,返回字符串最后一次出现的位置,如果没有匹配项则返回 -1。 |
| string.rindex( str, beg=0,end=len(string)) | 类似于 index(),不过是返回最后一个匹配到的子字符串的索引号。 |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.rpartition(str) | 类似于 partition()函数,不过是从右边开始查找 |
| string.rstrip() | 删除 string 字符串末尾的空格. |
| string.split(str=””, num=string.count(str)) | 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+1 个子字符串 |
| [string.splitlines(keepends]) | 按照行(‘\r’, ‘\r\n’, ‘\n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
| [string.strip(obj]) | 在 string 上执行 lstrip()和 rstrip() |
| string.swapcase() | 翻转 string 中的大小写 |
| string.title() | 返回”标题化”的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| string.translate(str, del=””) | 根据 str 给出的表(包含 256 个字符)转换 string 的字符,要过滤掉的字符放到 del 参数中 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.zfill(width) | 返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
字符串格式化
Python 字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
如下实例:
1 | #!/usr/bin/python |
以上实例输出结果:
1 | My name is Zara and weight is 21 kg! |
python 字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %F 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| 在正数前面显示空格 | |
| # | 在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’) |
| 0 | 显示的数字前面填充’0’而不是默认的空格 |
| % | ‘%%’输出一个单一的’%’ |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
三引号
1 | str12 = """ |

运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除 - x除以y | b / a 输出结果 2 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 0 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果 100000000000000000000 |
| // | 取整除 - 返回商的整数部分(向下取整) | >>> 9//2 4 >>> -9//2 -5 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1 。**~x** 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011,在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把”>>”左边的运算数的各二进位全部右移若干位,**>>** 右边的数字指定了移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔”与” - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔”或” - 如果 x 是非 0,它返回 x 的计算值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔”非” - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 ‘AND’ |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
条件判断 & 循环
条件判断基本语法格式
1 | if 判断条件: |
第二种elif
1 | if 判断条件1: |
循环
1 | str1 = "zheshi1sda" |
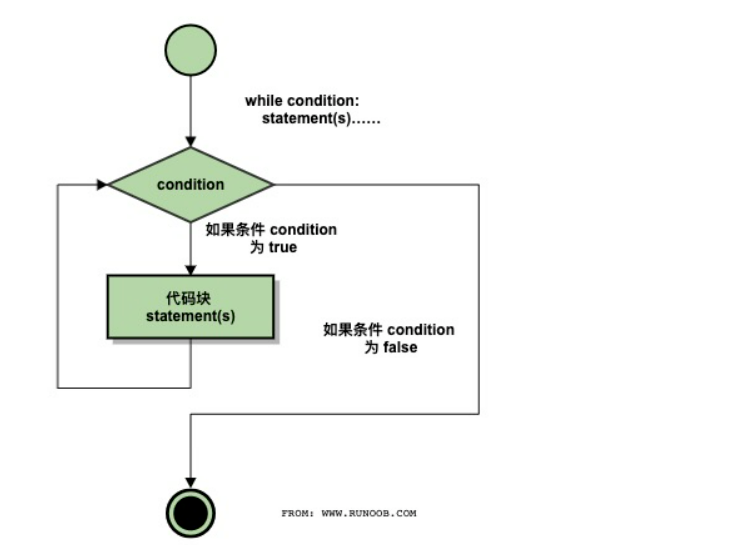
1 | while 判断条件(condition): |
日期时间
1 | localTime = time.localtime(time.time()) |

格式化日期符号
python中时间日期格式化符号:
- %y 两位数的年份表示(00-99)
- %Y 四位数的年份表示(000-9999)
- %m 月份(01-12)
- %d 月内中的一天(0-31)
- %H 24小时制小时数(0-23)
- %I 12小时制小时数(01-12)
- %M 分钟数(00-59)
- %S 秒(00-59)
- %a 本地简化星期名称
- %A 本地完整星期名称
- %b 本地简化的月份名称
- %B 本地完整的月份名称
- %c 本地相应的日期表示和时间表示
- %j 年内的一天(001-366)
- %p 本地A.M.或P.M.的等价符
- %U 一年中的星期数(00-53)星期天为星期的开始
- %w 星期(0-6),星期天为星期的开始
- %W 一年中的星期数(00-53)星期一为星期的开始
- %x 本地相应的日期表示
- %X 本地相应的时间表示
- %Z 当前时区的名称
- %% %号本身
获取某月日历
1 | cal = calendar.month(2016, 1) |

相关函数API
Time模块
| 序号 | 函数及描述 |
|---|---|
| 1 | time.altzone 返回格林威治西部的夏令时地区的偏移秒数。如果该地区在格林威治东部会返回负值(如西欧,包括英国)。对夏令时启用地区才能使用。 |
| 2 | [time.asctime(tupletime]) 接受时间元组并返回一个可读的形式为”Tue Dec 11 18:07:14 2008”(2008年12月11日 周二18时07分14秒)的24个字符的字符串。 |
| 3 | time.clock( ) 用以浮点数计算的秒数返回当前的CPU时间。用来衡量不同程序的耗时,比time.time()更有用。 |
| 4 | [time.ctime(secs]) 作用相当于asctime(localtime(secs)),未给参数相当于asctime() |
| 5 | [time.gmtime(secs]) 接收时间戳(1970纪元后经过的浮点秒数)并返回格林威治天文时间下的时间元组t。注:t.tm_isdst始终为0 |
| 6 | [time.localtime(secs]) 接收时间戳(1970纪元后经过的浮点秒数)并返回当地时间下的时间元组t(t.tm_isdst可取0或1,取决于当地当时是不是夏令时)。 |
| 7 | time.mktime(tupletime) 接受时间元组并返回时间戳(1970纪元后经过的浮点秒数)。 |
| 8 | time.sleep(secs) 推迟调用线程的运行,secs指秒数。 |
| 9 | [time.strftime(fmt,tupletime]) 接收以时间元组,并返回以可读字符串表示的当地时间,格式由fmt决定。 |
| 10 | time.strptime(str,fmt=’%a %b %d %H:%M:%S %Y’) 根据fmt的格式把一个时间字符串解析为时间元组。 |
| 11 | time.time( ) 返回当前时间的时间戳(1970纪元后经过的浮点秒数)。 |
| 12 | time.tzset() 根据环境变量TZ重新初始化时间相关设置。 |
Time模块包含了以下2个非常重要的属性:
| 序号 | 属性及描述 |
|---|---|
| 1 | time.timezone 属性 time.timezone 是当地时区(未启动夏令时)距离格林威治的偏移秒数(>0,美洲<=0大部分欧洲,亚洲,非洲)。 |
| 2 | time.tzname 属性time.tzname包含一对根据情况的不同而不同的字符串,分别是带夏令时的本地时区名称,和不带的。 |
日历模块
| 序号 | 函数及描述 |
|---|---|
| 1 | calendar.calendar(year,w=2,l=1,c=6) 返回一个多行字符串格式的year年年历,3个月一行,间隔距离为c。 每日宽度间隔为w字符。每行长度为21* W+18+2* C。l是每星期行数。 |
| 2 | calendar.firstweekday( ) 返回当前每周起始日期的设置。默认情况下,首次载入 calendar 模块时返回 0,即星期一。 |
| 3 | calendar.isleap(year) 是闰年返回 True,否则为 False。>>> import calendar >>> print(calendar.isleap(2000)) True >>> print(calendar.isleap(1900)) False |
| 4 | calendar.leapdays(y1,y2) 返回在Y1,Y2两年之间的闰年总数。 |
| 5 | calendar.month(year,month,w=2,l=1) 返回一个多行字符串格式的year年month月日历,两行标题,一周一行。每日宽度间隔为w字符。每行的长度为7* w+6。l是每星期的行数。 |
| 6 | calendar.monthcalendar(year,month) 返回一个整数的单层嵌套列表。每个子列表装载代表一个星期的整数。Year年month月外的日期都设为0;范围内的日子都由该月第几日表示,从1开始。 |
| 7 | calendar.monthrange(year,month) 返回两个整数。第一个是该月的星期几的日期码,第二个是该月的日期码。日从0(星期一)到6(星期日);月从1到12。 |
| 8 | calendar.prcal(year,w=2,l=1,c=6) 相当于 **print calendar.calendar(year,w=2,l=1,c=6)**。 |
| 9 | calendar.prmonth(year,month,w=2,l=1) 相当于 print calendar.month(year,month,w=2,l=1) 。 |
| 10 | calendar.setfirstweekday(weekday) 设置每周的起始日期码。0(星期一)到6(星期日)。 |
| 11 | calendar.timegm(tupletime) 和time.gmtime相反:接受一个时间元组形式,返回该时刻的时间戳(1970纪元后经过的浮点秒数)。 |
| 12 | calendar.weekday(year,month,day) 返回给定日期的日期码。0(星期一)到6(星期日)。月份为 1(一月) 到 12(12月)。 |
函数
简单语法
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,**后接函数标识符名称和圆括号()**。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
1 | def greet(name): |
I/O 文件
Python 提供了必要的函数和方法进行默认情况下的文件基本操作。你可以用 file 对象做大部分的文件操作。
open 函数
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法:
1 | file object = open(file_name [, access_mode][, buffering]) |
各个参数的细节如下:
- file_name:file_name 变量是一个包含了你要访问的文件名称的字符串值。
- access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
- buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
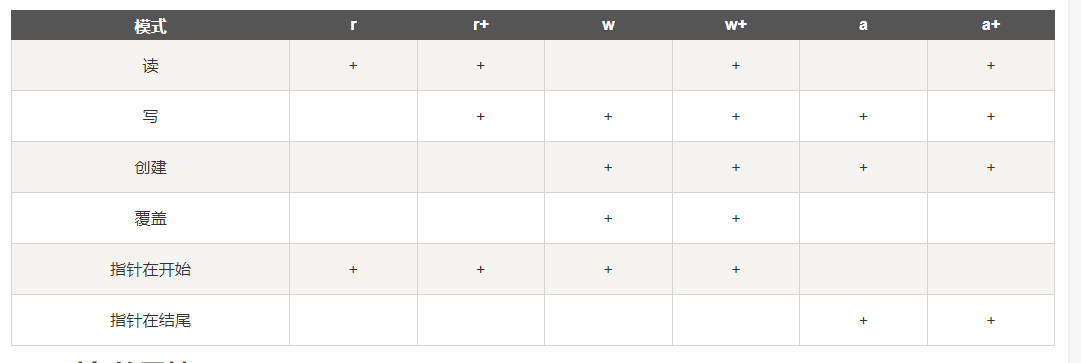
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
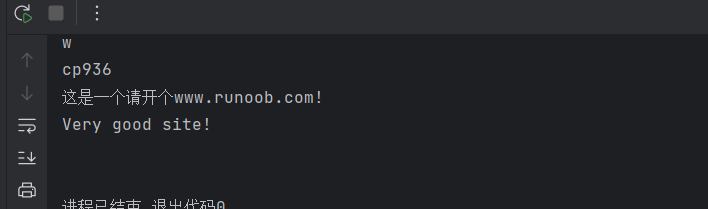
1 | if __name__ == '__main__': |

文件定位
1 | # 打开一个文件 |
重命名文件 和 删除文件
ython的os模块提供了帮你执行文件处理操作的方法,比如重命名和删除文件。
要使用这个模块,你必须先导入它,然后才可以调用相关的各种功能。
rename() 方法
rename() 方法需要两个参数,当前的文件名和新文件名。
语法:
1 | os.rename(current_file_name, new_file_name) |
remove()方法
你可以用remove()方法删除文件,需要提供要删除的文件名作为参数。
语法:
1 | os.remove(file_name) |
目录操作
所有文件都包含在各个不同的目录下,不过Python也能轻松处理。os模块有许多方法能帮你创建,删除和更改目录。
mkdir()方法
可以使用os模块的mkdir()方法在当前目录下创建新的目录们。你需要提供一个包含了要创建的目录名称的参数。
语法:
1 | os.mkdir("newdir") |
chdir()方法- –改变
可以用chdir()方法来改变当前的目录。chdir()方法需要的一个参数是你想设成当前目录的目录名称。
语法:
1 | os.chdir("newdir") |
getcwd() 方法—显示
getcwd()方法显示当前的工作目录。
语法:
1 | os.getcwd() |
rmdir()方法—删除
rmdir()方法删除目录,目录名称以参数传递。
在删除这个目录之前,它的所有内容应该先被清除。
语法:
1 | os.rmdir('dirname') |
文件相关的API
https://www.runoob.com/python/os-file-methods.html
异常处理
基本使用
1 | try: |
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
1 | if __name__ == '__main__': |
面向对象技术
1 | class ClassName: |
创建类
1 | class Employee: |
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
而 __self.class__ 则指向类。
继承类—-类的继承
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。
通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
继承语法
1 | class 派生类名(基类名) |
在python中继承中的一些特点:
- 1、如果在子类中需要父类的构造方法就需要显式的调用父类的构造方法,或者不重写父类的构造方法。
- 2、在调用基类的方法时,需要加上基类的类名前缀,且需要带上 self 参数变量。区别在于类中调用普通函数时并不需要带上 self 参数
- 3、Python 总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
如果在继承元组中列了一个以上的类,那么它就被称作”多重继承” 。
语法:
派生类的声明,与他们的父类类似,继承的基类列表跟在类名之后,如下所示:
1 | class SubClassName (ParentClass1[, ParentClass2, ...]): |
类属性和方法
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的方法
在类的内部,使用 def 关键字可以为类定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,不能在类的外部调用。在类的内部调用 self.__private_methods
1 | class JustCounter: |
Python不允许实例化的类访问私有数据,但你可以使用 **object._className__attrName**( 对象名._类名__私有属性名 )访问属性
单下划线、双下划线、头尾双下划线说明:
__foo__: 定义的是特殊方法,一般是系统定义名字 ,类似 init() 之类的。_foo:以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。
通过使用get/set__私有属性 ,来操作私有属性, 而不是直接通过类名来操作 。这样符合类的操作规范
注意事项
print输出相关
如果输出的数据类型是基本类型 ,也就是 int 、float 、 complex等等。 那么就不能用字符串拼接的方法输出
1 | # count确定是int类型 |
快速生成变量名
1 | Ctrl + Alt + V |




