
网络层
导论
学习目标:
理解网络服务的基本原理,聚焦于其数据平面
- 网络服务模型
- 转发和路由
- 路由器工作原理
- 通用转发
- 互联网中网络层协议的实例和实现
网络层的服务
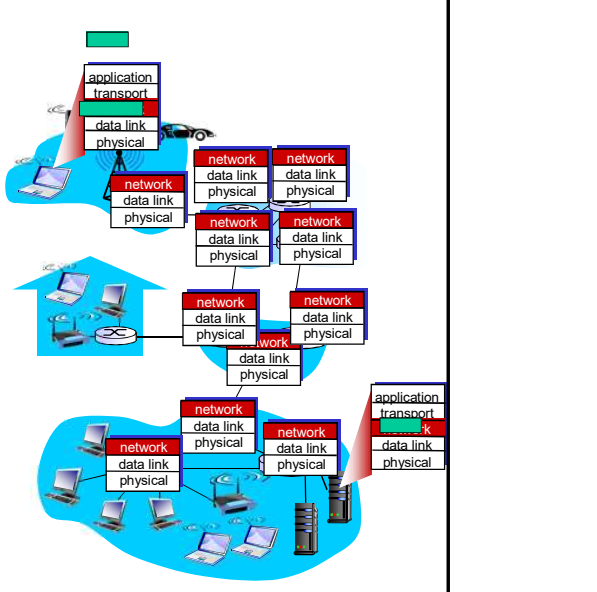
- 在发送主机和接收主机对之间传送段(TCP/UDP)(segment)
- 在发送端将段封装到数据报(Datagram)中
- 在接收端,将段上交给传输层 实体
- 网络层协议存在于每一个主机 和路由器
- 路由器检查每一个经过它的 IP 数据报的头部
- 最后在目标端解封装数据包, 将其恢复。交给TCP/UDP
转发
网络层的关键功能
** 转发: 将分组从路由器 的输入接口转发到合适 的输出接口 **
转发是通过单个路口的 过程 。是局部的功能
** 路由: 使用路由算法来 决定分组从发送主机到 目标接收主机的路径 **
路由是从端到端的路径, 从源到目的的路 由路径规划过程 。从源主机发送到模板主机。 是一个全局的功能
网络层: 数据平面、控制平面
数据平面 (局部的功能)
转发是数据平面的功能
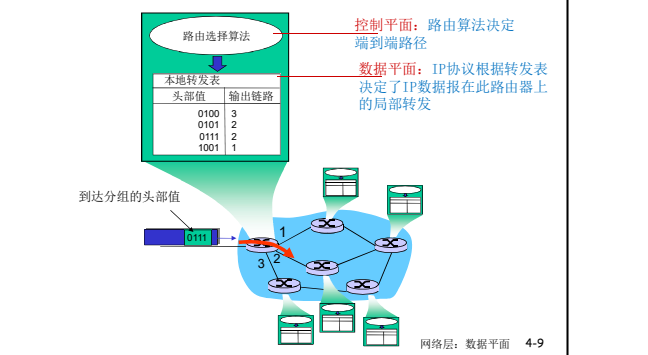
数据平面的作用是对每个到来的数据实现怎么样的处理
- 本地,每个路由器功能
- 决定从路由器输入端口 到达的分组如何转发到 输出端口
- **转发功能: **
- **传统方式:基于目标地址+转发表 **
- **SDN方式:基于多个 字段+流表 **
控制平面 (全局的功能)
- 网络范围内的逻辑
- 决定数据报如何在路由器之间 路由,决定数据报从源到目标 主机之间的端到端路径
- **2个控制平面方法: **
- ** 传统的路由算法: 在路由器 中被实现 **
- ** software-defined networking (SDN): 在远程的服务器中 实现 **
路由器是控制平面的功能, 而转发是数据平面的功能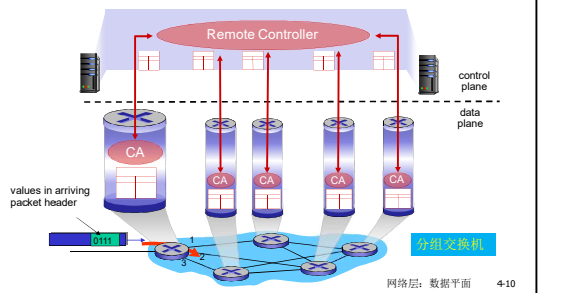
** SDN方式:逻辑集中的控制平面**
一个不同的(通常是远程的)控制器与本地控制代理(CAs) 交互
** 传统方式:路由和转发的相互作用**
传统方式较为僵化,很难进行改变
网络服务模型
从发送方主机到接收方主机传输数据报的“通道” ,网络提供对单个数据和数据报流的服务
- 对于单个数据报的服务:
可靠传送;延迟保证
- 对于数据报流的服务:
保证数据报流传送; 保证流的最小带宽;分组之间的延迟差。
连接建立
在某些网络架构中是网络连接建立第三个重要的功能, 例如: ATM、frame relay
**在分组传输之前,在两个主机之间,在通过一些 路由器所构成的路径上建立一个网络层连接 **
** 网络层和传输层连接服务区别: **
- 网络层: 在2个主机之间,涉及到路径上的一些路由器
- 传输层: 在2个进程之间,很可能只体现在端系统上 (TCP连接)
路由器的组成
待深入学习, 相关内容还未理解
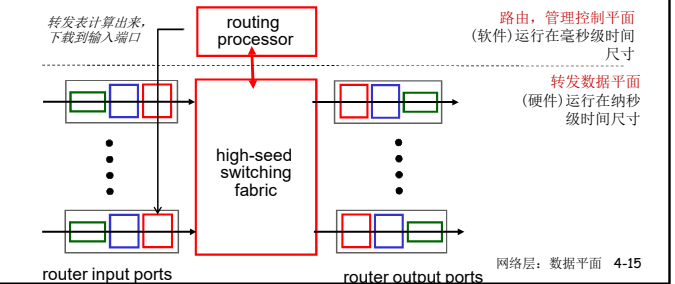
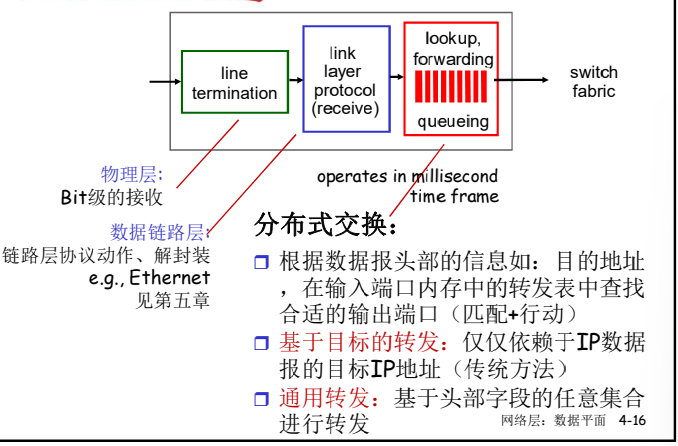
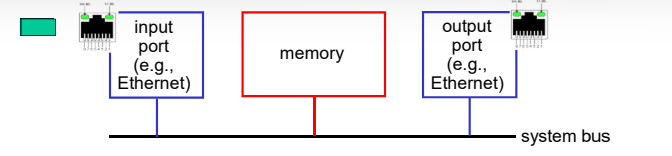
路由器结构概况
高层面(非常简化的)通用路由器体系架构
- 路由:运行路由选择算法/协议 (RIP, OSPF, BGP)-生成 路由表
- 转发:从输入到输出链路交换数据报-根据路由表进行分组的转发
输入/输出端口功能
路由器的输入端口和输出端口通常是整合在一起的
当数据报从交换机构的到达速度比传输速率快 就需要输出端口缓存
由调度规则选择排队的数据报进行传输
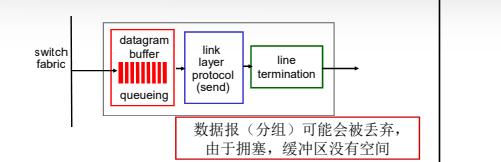
输出端口排队:
- 假设交换速率Rswitch是Rline的N倍(N:输入端口的数量)
- 当多个输入端口同时向输出端口发送时,缓冲该分组(当通 过交换网络到达的速率超过输出速率则缓存)
- 排队带来延迟,由于输出端口缓存溢出则丢弃数据报!
最长前缀匹配
最长前缀匹配:在路由器中经常采用TCAMs( ternary content addressable memories)硬 件来完成
- 内容可寻址:将地址交给TCAM,它可以在一个时 钟周期内检索出地址,不管表空间有多大
- Cisco Catalyst系列路由器: 在TCAM中可以存储多达 约为1百万条路由表项
当给定目标地址查找转发表时,采用最长地址前 缀匹配的目标地址表项


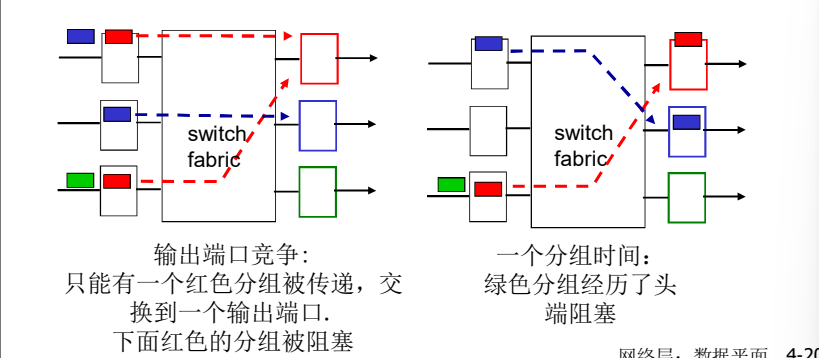
输入端口缓存
当交换机构的速率小于输入端口的汇聚速率时 -> 在输入端口可能要排队
- 排队延迟以及由于输入缓存溢出造成丢失!
Head-of-the-Line (HOL) blocking: 排在队头的数据报 阻止了队列中其他数据报向前移动
调度机制
调度: 选择下一个要通过链路传输的分组 (取决于调度规则)
- FIFO (first in first out) scheduling: 按照分组到来的次序发送
- 丢弃 丢弃策略: 如果分组到达一个满的队列,哪个分组将会被抛弃?
- tail drop: 丢弃刚到达的分组
- priority: 根据优先权丢失/移除分组
- random: 随机地丢弃/移除
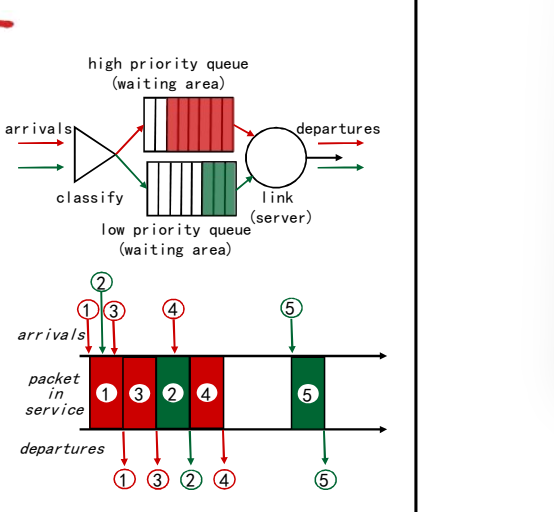
- 优先权调度:发送最高优先 权的分组
- 多类,不同类别有不同的 优先权
- 类别可能依赖于标记或者其 他的头部字段, e.g. IP source/dest, port numbers, ds,etc.
- 先传高优先级的队列中的分 组,除非没有
- 高(低)优先权中的分组传 输次序:FIFO
- 现实生活中的例
- 其他策略 : Round Robin (RR) scheduling:
循环扫描不同类型的队列, 发送完一类的一个分组 ,再发送下一个类的一个分组,循环所有类
交换结构
将分组从输入缓冲区传输到合适的输出端口
交换速率:分组可以按照该速率从输入传输到输 出
- 运行速度经常是输入/输出链路速率的若干倍
- N 个输入端口:交换机构的交换速度是输入线路速度的N倍比较理 想,才不会成为瓶颈
三种典型的交换机构:
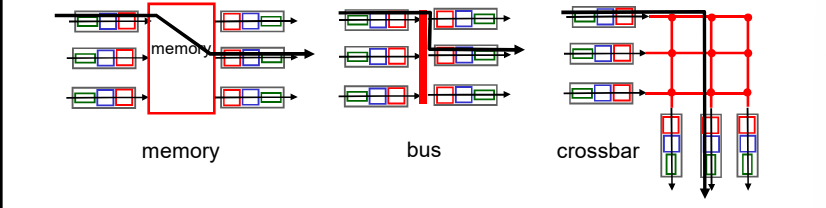
第一种:通过内存交换
早期使用这种方式:
在CPU直接控制下的交换,采用传统的计算机
分组被拷贝到系统内存,CPU从分组的头部提取出目标 地址,查找转发表,找到对应的输出端口,拷贝到输出 端口
转发速率被内存的带宽限制 (数据报通过BUS两遍)
一次只能转发一个分组
第二种: 通过总线交换(bus)
数据报通过共享总线,从输入端 口转发到输出端口
总线竞争: 交换速度受限于总线 带宽
1次处理一个分组
1 Gbps bus, Cisco 1900; 32 Gbps bus, Cisco 5600;对于接 入或企业级路由器,速度足够( 但不适合区域或骨干网络)
第三种:通过互联网络(crossbar等)的交换
同时并发转发多个分组,克服总线带宽 限制
- Banyan(榕树)网络,crossbar(纵横) 和其它的互联网络被开发,将多个处理 器连接成多处理器
当分组从端口A到达,转给端口Y;控 制器短接相应的两个总线
高级设计:将数据报分片为固定长度的信元,通过交换网络交换
Cisco12000:以60Gbps的交换速率通 过互联网络






