
拥塞控制
拥塞控制原理(网络的问题)
拥塞:
非正式的定义: “太多的数据需要网络传输,超过了网络的处理能力”
与流量控制不同
拥塞的表现:
- 分组丢失 (路由器缓冲区溢出)
- **分组经历比较长的延迟(**在路由器的队列中排队)
拥塞的原因/代价
1. 场景一:
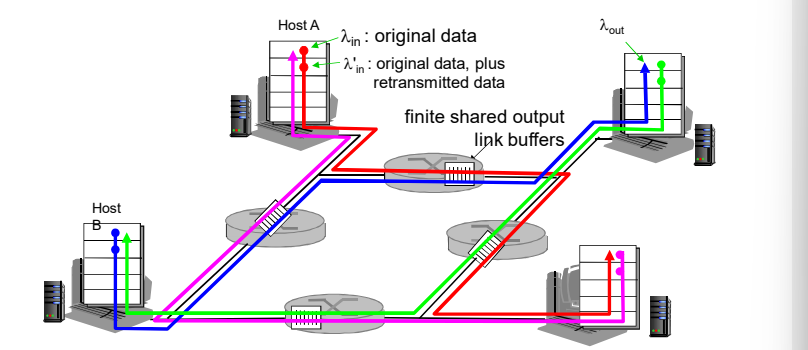
主机A 向 C发送; 主机B向D 发送。都通过一个路由器,路由器的容量(带宽) 是:R (单位: bps)
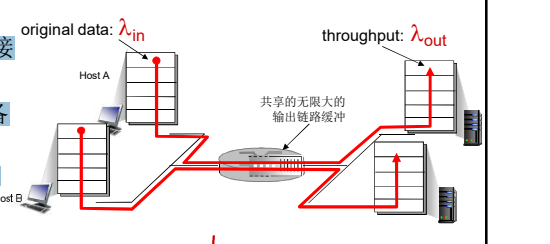
- 2个发送端,2个接 收端
- 一个路由器,具备 无限大的缓冲
- 输出链路带宽:R
- 没有重传
2. 场景2:
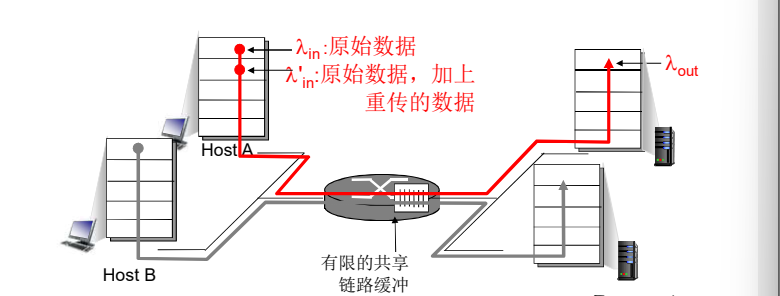
- 一个路由器,有限的缓冲
- 分组丢失时,发送端重传
- 应用层的输入=应用层输出:
- 传输层的输入包括重传:

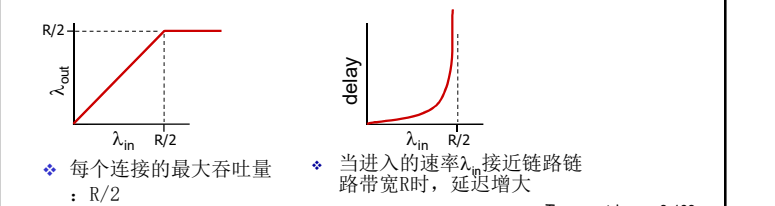
缓冲区无限和有限的情况下 :
理想化: 发送端有完美的信息 发送端知道什么时候路由器的缓冲是可用的
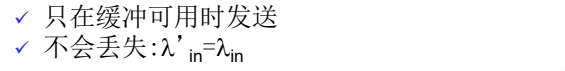
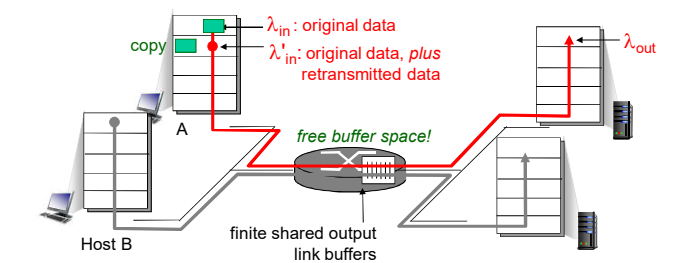
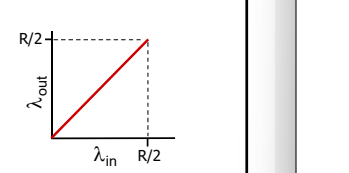 输入输出变了, 但是延迟并没有改变。和场景一中的延迟图是一样的。
输入输出变了, 但是延迟并没有改变。和场景一中的延迟图是一样的。
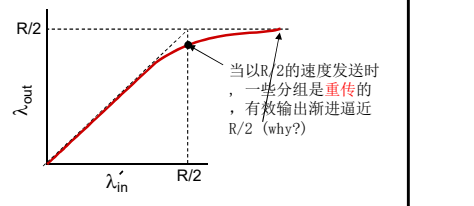
现实情况: 重复
- 分组可能丢失,由于缓冲器 满而被丢弃
- 发送端最终超时,发送第2 个拷贝,2个分组都被传出
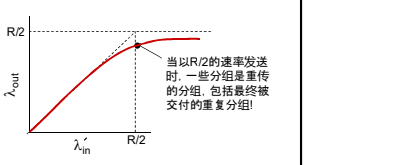
输出比输入少原因:1)重传的丢失分组;2) 没有必要重传的重复分组
拥塞的“代价”:
因为有大量的重传, 所以我们并不知道网络中传输的有效数据是多少, 类比平时使用激光枪时应该是指哪打哪, 但是在月球上, 失重之后,为了打中目标,就需要抬高枪口。所以这里我们为了达到有效数据的传输量(理想的蹦出), 但是传输中又有大量的重传数据, 所以就需加大输出的量。
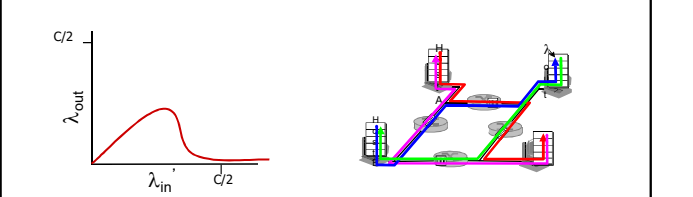
3. 场景3
4个发送端;多重路径;超时重传
当lamda in 等都增加时, 所有的蓝色分组都在最上方的队列中丢失,蓝色的吞吐 -> 0
又一个拥塞的代价:
当分组丢失时,任何“关于这个分组的上游传输能力” 都被浪费了
拥塞控制方法
1. 端到端拥塞控制:
- 没有来自网络的显式反馈(从而端系统决定加大或者降低发送速率)
- 端系统根据延迟和 丢失事件推断是否 有拥塞
- TCP采用的方法
2. 网络辅助的拥塞控制:
路由器提供给端系统以 反馈信息
- 单个bit置位,显示有 拥塞 (SNA, DECbit, TCP/IP ECN, ATM)
- 显式提供发送端可以 采用的速率
案例: ATM的异步传输网络的 ABR拥塞控制
ABR: available bit rate:
提供的服务是 “弹性服务”
如果发送端的路径“轻载 ”
- 发送方使用可用带宽
如果发送方的路径拥塞了
- 发送方限制其发送的 速度到一个最小保障(1兆bps) 速率上
RM (资源管理) 信元: 一个小的分组, 只有53个字节(5个字节的头部,48个字节的数据载荷部分)
信元的范围: bit < 信元 < 分组
信元在每个单位节点中仅仅耽误53个bit , 没有分组的那么大。
由发送端发送,在数据信元中 间隔插入
RM信元中的比特被交换机设 置 (“网络辅助”)
- NI bit: no increase in rate (轻微拥塞)速率不要 增加了 [拥塞就扔 ]
- CI bit: congestion indication 拥塞指示
发送端发送的RM 信元被接 收端返回, 接收端不做任何 改变
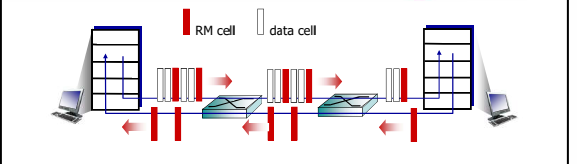
在RM信元中的2个字节 ER (explicit rate)字段
- 拥塞的交换机可能会降低信元中ER的值
- 发送端发送速度因此是最低的可支持速率
数据信元中的EFCI bit: 被拥塞的交换机设置成1
- 如果在管理信元RM前面的数据信元EFCI被设置成了1, 接收端在 返回的RM信元中设置CI bit
TCP 拥塞控制
端到端的拥塞控制机制
如果每次都反馈相关的信息 ,那么对网络的负担就非常大了
路由器不向主机有关拥塞的反馈信息
- • 路由器的负担较轻
- • 符合网络核心简单的 TCP/IP架构原则
端系统根据自身得到的信息 ,判断是否发生拥塞,从而 采取动作
拥塞控制的几个问题
- 如何检测拥塞 【轻微拥塞 / 拥塞】
- 控制的策略是什么?
- 在拥塞发送时如何动 作,降低速率 【 在轻微拥塞 / 拥塞 如何降低 ? 】
- 在拥塞缓解时如何动 作,增加速率
拥塞感知
发送端如何探测到拥塞?
- 某个段超时了(丢失事件 ):****拥塞

- 超时时间到,某个段的确认没有来 (一直重读ACK =3460的确认,只有一个正常,剩下都是冗余)
- 原因1:网络拥塞(某个路由器缓冲区没空间了,被丢弃)概率大
- 原因2:出错被丢弃了(各级错误,传输过程中没有通过校验,被丢弃)概率小
- 一旦超时,就认为拥塞了,有一定误判,但是总体控制方向是对的
- 有关某个段的3次重复ACK:****轻微拥塞
- 段的第1个ack,正常,确认绿段,期待红段
- 段的第2个重复ack,意味着红段的后一段收到了,蓝段乱序到达
- 段的第2、3、4个ack重复,意味着红段的后第2、3、4个段收到了 ,橙段乱序到达,同时红段丢失的可能性很大(后面3个段都到了, 红段都没到)
- 网络这时还能够进行一定程度的传输,拥塞但情况要比第一种好
速率控制的方法:
如何控制发送端发送的速率

- 维持一个拥塞窗口的值:CongWin
- 发送端限制已发送但是未确认的数据量(的上限): LastByteSent-LastByteAcked <= CongWin
- 从而粗略地控制发送方的往网络中注入的速率
CongWin是动态的,是感知到的网络拥塞程度的函数
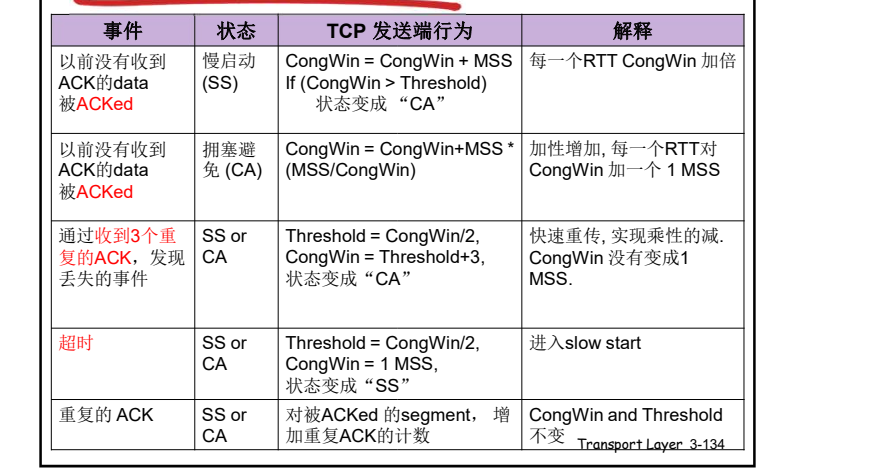
超时或者3个重复ack,CongWin↓
- 超时时:CongWin降为1MSS,进入SS阶段然后再倍增到 CongWin/2(每个RTT),从而进入CA阶段 (MSS:最大报文段大小 .**往返延时(RTT)**)
- 3个重复ack :CongWin降为CongWin/2,CA阶段(CA: 拥塞避免)
否则(正常收到Ack,没有发送以上情况):CongWin跃跃欲试↑
- SS阶段:加倍增加(每个RTT) (SS: 慢启动)
- CA阶段:线性增加(每个RTT)
联合控制的方法:
发送端控制发送但是未确认的量同时也不能够超过接收 窗口,满足流量控制要求
- SendWin=min{CongWin, RecvWin}
- 同时满足 拥塞控制和流量控制要求
拥塞控制策略:
- 慢启动
- AIMD:线性增、乘性减少
- 超时事件后的保守策略
TCP拥塞控制: 慢启动
- 连接刚建立, CongWin = 1 MSS
- 如: MSS = 1460bytes & RTT = 200 msec
- 初始速率 = 58.4kbps
- 可用带宽可能>> MSS/RTT
- 应该尽快加速,到达希望的 速率
- 当连接开始时,指数性增 加发送速率,直到发生丢 失的事件
- 启动初值很低
- 但是速度很快
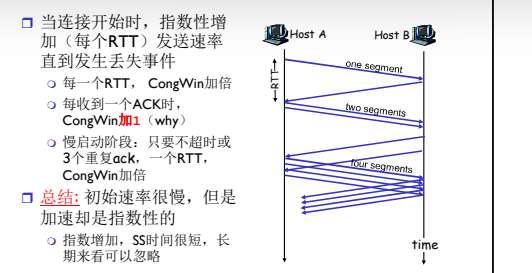
TCP 拥塞控制:AIMD
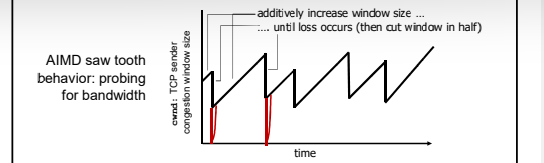
- 乘性减:
丢失事件后将CongWin降为1, 将CongWin/2作为阈值,进 入慢启动阶段(倍增直到 CongWin/2)
- 加性增:
当CongWin>阈值时,一个 RTT如没有发生丢失事件 ,将CongWin加1MSS: 探 测
当收到3个重复的ACKs:
- CongWin 减半
- 窗口(缓冲区大小)之后 线性增长
当超时事件发生时:
- CongWin被设置成 1 MSS,进入SS阶段
- 之后窗口指数增长
- 增长到一个阈值(上次发 生拥塞的窗口的一半)时 ,再线性增加
3个重复的ACK表示网络 还有一定的段传输能力
超时之前的3个重复的 ACK表示“警报”
TCP 拥塞控制:超时事件后的保守策略
问: 什么时候应该将 指数性增长变成 线性?
答: 在超时之前,当 CongWin变成上 次发生超时的窗口的一半
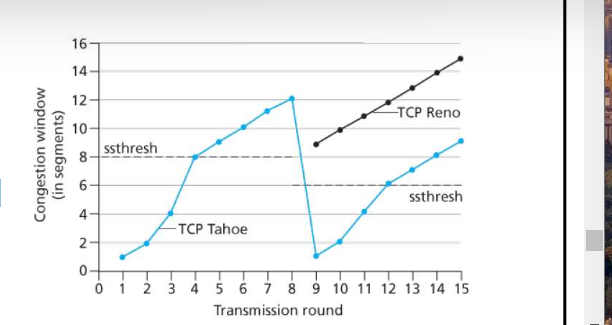
实现:
- 变量:Threshold
- 出现丢失,Threshold设置成 CongWin的1/2
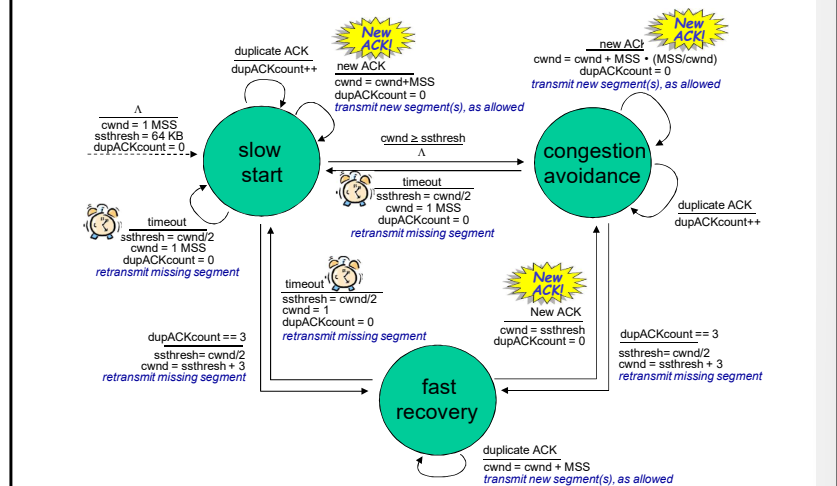
总结: TCP拥塞控制
- 当CongWin<Threshold, 发送端处于慢启动阶段( slow-start), 窗口指数性增长.
- 当CongWin〉Threshold, 发送端处于拥塞避免阶段 (congestion-avoidance), 窗口线性增长.
- 当收到三个重复的ACKs (triple duplicate ACK), Threshold设置成 CongWin/2, CongWin=Threshold+3.
- 当超时事件发生时timeout, Threshold=CongWin/2 CongWin=1 MSS,进入SS阶段
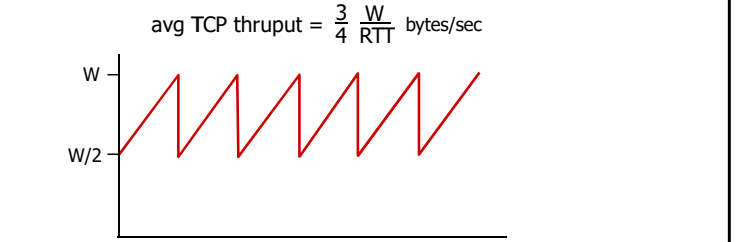
TCP吞吐量
TCP的平均吞吐量是多少,使用窗口window尺寸W和RTT来 描述?
忽略慢启动阶段,假设发送端总有数据传输
W:发生丢失事件时的窗口尺寸(单位:字节)
- 平均窗口尺寸(#in-flight字节):3/4W
- 平均吞吐量:RTT时间吞吐3/4W
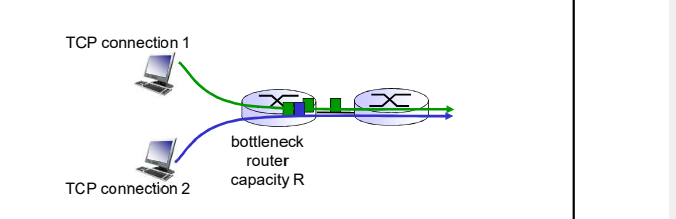
TCP的公平性
公平性目标: 如果 K个TCP会话分享一个链路带宽为R的 瓶颈,每一个会话的有效带宽为 R/K
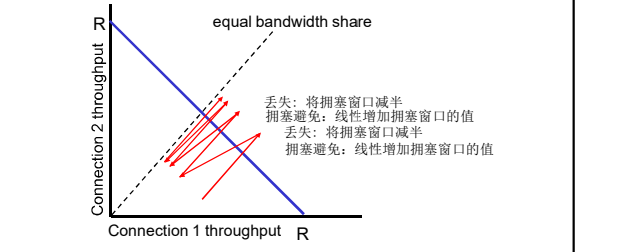
为什么TCP是公平的 ?
2个竞争的TCP会话:
- 加性增加,斜率为1, 吞吐量增加
- 乘性减,吞吐量比例减少
公平性和 UDP
多媒体应用通常不是用 TCP
- 应用发送的数据速率希望 不受拥塞控制的节制
使用UDP:
- 音视频应用泵出数据的速 率是恒定的, 忽略数据的 丢失
研究领域: TCP 友好性
公平性和并行TCP连接
2个主机间可以打开多个并行的TCP连接
Web浏览器
例如: 带宽为R的链路支持了 9个连接;
- 如果新的应用要求建1个TCP连 接,获得带宽R/10
- 如果新的应用要求建11个TCP连接,获得带宽R/2







