网络层控制平面
主要学习网络层控制平面的工作原理
路由(route)的概念
**路由: 按照某种指标(传输延迟,所经过的站点数目等)找到一条 从源节点到目标节点的较好路径 **
- 较好路径: 按照某种指标较小的路径
- 指标:站数, 延迟,费用,队列长度等, 或者是一些单纯指标的加权平均
- 采用什么样的指标,表示网络使用者希望网络在什么方面表现突出,什 么指标网络使用者比较重视
** 以网络为单位进行路由(路由信息通告+路由计算) **
- 网络为单位进行路由,路由信息传输、计算和匹配的代价低
- 前提条件是:一个网络所有节点地址前缀相同,且物理上聚集
- 路由就是:计算网络 到其他网络如何走的问题
** 路由选择算法(routing algorithm):网络层软件的一部分,完成 路由功能 **
网络的图抽象
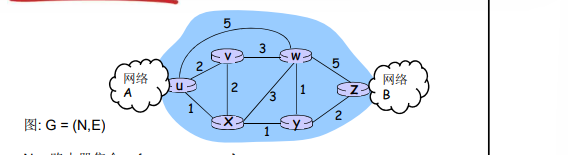
N = 路由器集合 = { u, v, w, x, y, z }
E = 链路集合 ={ (u,v), (u,x), (v,x), (v,w), (x,w), (x,y), (w,y), (w,z), (y,z) }边有代价
**边的代价: **
- c(x,x’) = 链路的代价 (x,x’) - e.g., c(w,z) = 5
- 代价可能总为1
- 或是 链路带宽的倒数
- 或是 拥塞情况的倒数
**路由的输入:拓扑、边的代价、源节点 **
**输出的输出:源节点的汇集树(到其他节点的路径) **
汇集树下面解释
路由最优化原则 (optimality principle)
最优化原则
汇集树(sink tree)
- **此节点到所有其它节点的最优路径形成的树 **
- 路由选择算法就是为所有路由器找到并使用汇集树
路由原则
- **正确性(correctness):**算法必须是正确的和完整的,使分 组一站一站接力,正确发向目标站;完整:目标所有的 站地址,在路由表中都能找到相应的表项;没有处理不 了的目标站地址;
- 简单性(simplicity):算法在计算机上应简单:最优但复杂 的算法,时间上延迟很大,不实用,不应为了获取路由 信息增加很多的通信量;
- **健壮性(robustness):**算法应能适应通信量和网络拓扑的 变化:通信量变化,网络拓扑的变化算法能很快适应; 不向很拥挤的链路发数据,不向断了的链路发送数据;
- **稳定性(stability)**:产生的路由不应该摇摆
- 公平性(fairness):对每一个站点都公平
- **最优性(optimality)**:某一个指标的最优,时间上,费用 上,等指标,或综合指标;实际上,获取最优的结果代 价较高,可以是次优的
路由算法的分类
- ** 全局算法 —> “link state” 算法 **
** 所有的路由器拥有完整的拓扑 和边的代价的信息 **
- **分布式算法 —-> “distance vector” 算法 **
路由器只知道与它有物理连接 关系的邻居路由器,和到相应 邻居路由器的代价值
叠代地与邻居交换路由信息、 计算路由信息
传统的路由选择算法
**“link state” 算法 **
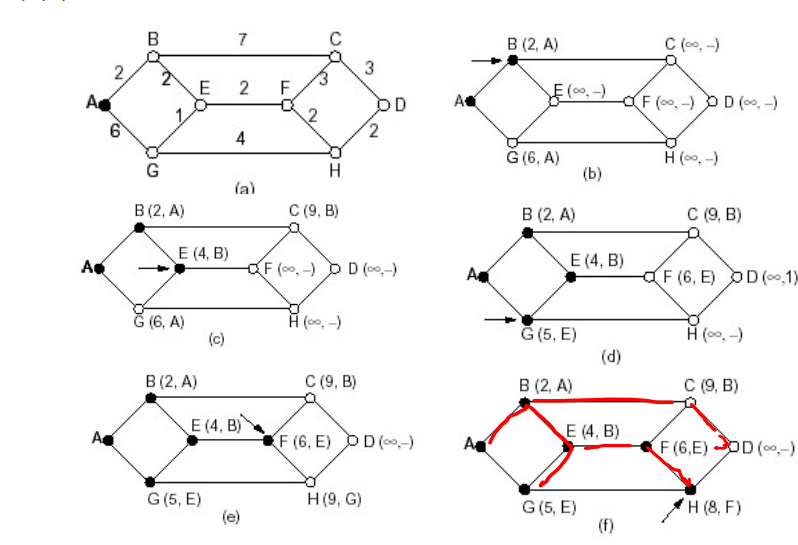
LS路由的工作过程
配置LS路由选择算法的路由工作过程
- 各点通过各种渠道获得整个网络拓扑, 网络中所有链路 代价等信息(这部分和算法没关系,属于协议和实现)
- 使用LS路由算法,计算本站点到其它站点的最优路径(汇 集树),得到路由表
- 按照此**路由表转发分组(datagram方式) **
- 严格意义上说不是路由的一个步骤
- 分发到输入端口的网络层

LS路由的基本工作过程
- 发现相邻节点,获知对方网络地址
一个路由器上电之后,向所有线路发送HELLO分组
其它路由器收到HELLO分组,回送应答,在应答分组中,告 知自己的名字(全局唯一)
在LAN中,通过广播HELLO分组,获得其它路由器的信息, 可以认为引入一个人工节点

- 测量到相邻节点的代价(延迟,开销)
实测法
发送一个分组要求对方立即响应
回送一个ECHO分组
通过测量时间可以估算出延迟情况
- 组装一个LS分组**,描述它到相邻节点的代价情况**
发送者名称 序号,年龄
列表: 给出它相邻节点,和它到相邻节点的延迟
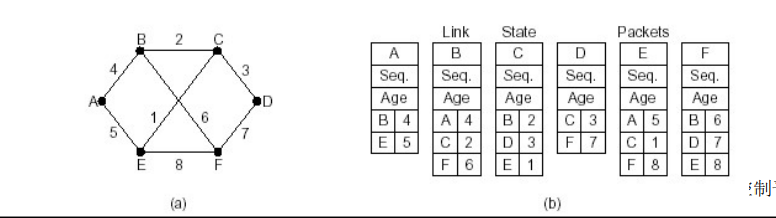
- 将分组通过扩散的方法发到所有其它路由器以上4步让每个路由器获得拓扑和边代价
顺序号:用于控制无穷的扩散,每个路由器都记录( 源路由器,顺序号),发现重复的或老的就不扩散
** 将分组通过扩散的方法发到所有其它路由器 **
- 通过Dijkstra算法找出最短路径(这才是路由算法)
- 每个节点独立算出来到其他节点(路由器=网络)的最短路径
- 迭代算法:第k步能够知道本节点到k个其他节点的最短路径
** 通过Dijkstra算法找出最短路径 (路由算法)前面的只是铺垫,通过协议发现邻居,通过网络的泛洪来散播路由信息**
链路状态路由选择(link state routing)
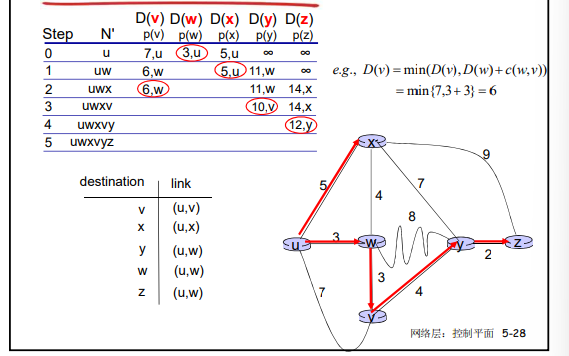
**符号标记: **
- c(i,j): 从节点i 到j链路代价(初始状态下非相邻节点之间的 链路代价为∞)
- D(v): 从源节点到节点V的当前路径代价(节点的代价)
- p(v): 从源到节点V的路径前序节点
- N’: 当前已经知道最优路径的的节点集合(永久节点的集合)
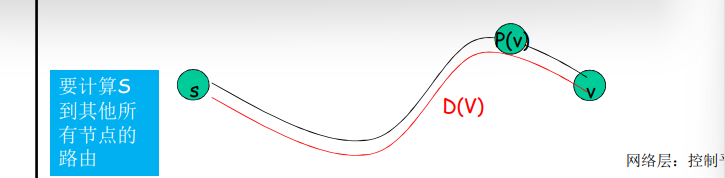
LS路由选择算法的工作原理
** 节点标记: 每一个节点使用(D(v),p(v)) 如: (3,B)标记 **
- D(v)从源节点由已知最优路径到达本节点的距离
- P(v)前序节点来标注
** 2类节点 **
- 临时节点(tentative node) :还没有找到从源 节点到此节点的最优路径的节点
- 永久节点(permanent node) N’:已经找到了从 源节点到此节点的最优路径的节点
**初始化 **
- 除了源节点外,所有节点都为临时节点
节点代价除了与源节点代价相邻的节点外,都为∞
从所有临时节点中找到一个
- 节点代价最小的临时节点,将 之变成永久节点(当前节点)W
- 对此节点的所有在临时节点集合中的邻节点(V)
如 D(v)>D(w) + c(w,v), 则重新标注此点, (D(W)+C(W,V), W)
否则,不重新标注
- 开始一个新的循环
**“distance vector” 算法 **
**距离矢量路由选择(distance vector routing) **
- ** 动态路由算法之一 **
** 距离矢量路由选择的基本思想 **
- 各路由器维护一张路由表,结构如图(其它代价)

- 各路由器与相邻路由器交换路由表
- 根据获得的路由信息,更新路由表
**代价及相邻节点间代价的获得 **
- 跳数(hops), 延迟(delay),队列长度
- 相邻节点间代价的获得:通过实测
** 路由信息的更新 **
- 根据实测 得到本节点A到相邻站点的代价(如:延迟)
- 根据各相邻站点声称它们到目标站点B的代价
- 计算出本站点A经过各相邻站点到目标站点B的代价
- 找到一个最小的代价,和相应的下一个节点Z,到达节点 B经过此节点Z,并且代价为A-Z-B的代价
- 其它所有的目标节点一个计算法
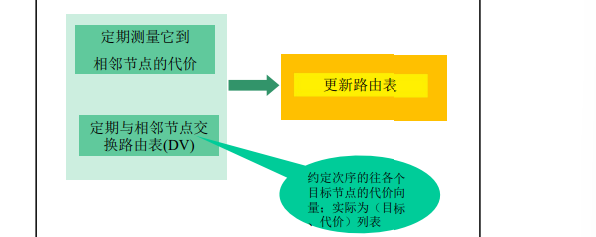
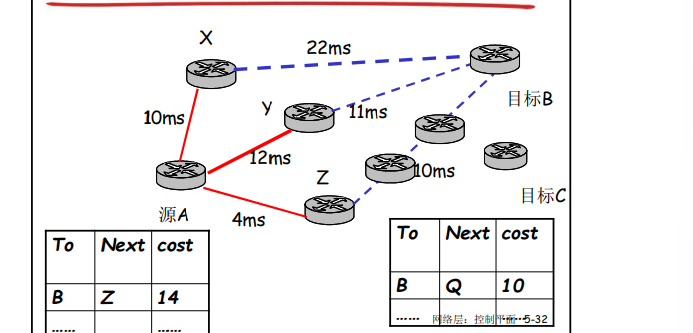
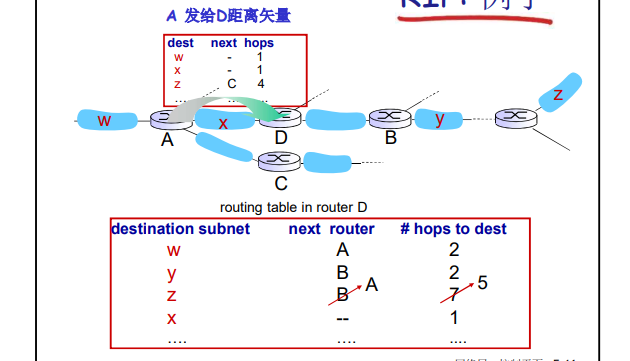
举例: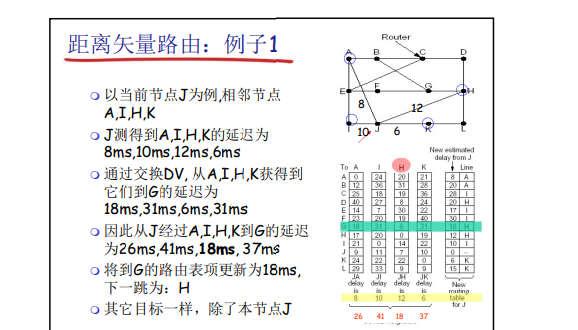
**距离矢量算法: **
** Bellman-Ford 方程(动态规划) **
递归找到最小值, 通过局部最小得到全局最小值。
** Dx (y) = 节点x到y代价最小值的估计 **[ x 节点维护距离矢量Dx = [Dx (y): y є N ] ]
** 节点x: **
- 知道到所有邻居v的代价: c(x,v)
- 收到并维护一个它邻居的距离矢量集
- 对于每个邻居, x 维护 Dv = [Dv (y): y є N ]
距离矢量算法核心思路
每个节点都将自己的距离矢量估计值传送给邻居,定时或者 DV有变化时,让对方去算
** 当x从邻居收到DV时,自己运算,更新它自己的距离矢量 **
**采用B-F equation: **
{ Dx (y) ← minv {c(x,v) + Dv (y)} 对于每个节点y ∊ N }
{ X往y的代价 x到邻居v代价 v声称到y的代价 }
** Dx (y)估计值最终收敛于实际的最小代价值dx (y) **
** 距离矢量算法 是 异步式迭代, 每次本地迭代 被以下事件触发 **
[1. 本地链路代价变化了 2. 从邻居来了DV的更新消息 ]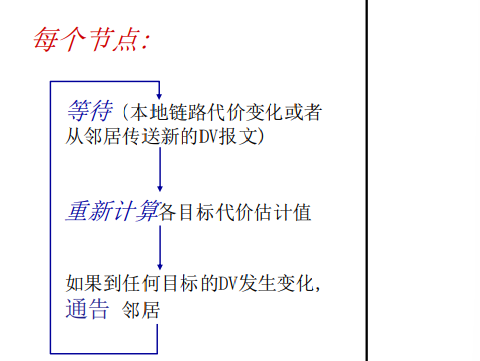
两个算法的比较
** 消息复杂度 DV算法更好一些**
LS: 有 n 节点, E 条链路,发送 报文O(nE)个
局部的路由信息;全局传播
DV: 只和邻居交换信息
全局的路由信息,局部传播
** 收敛时间 LS更好**
LS: O(n2) 算法 有可能震荡
DV: 收敛较慢 可能存在路由环路
** 健壮性: 路由器故障会发生什么 (LS胜出) **
LS:
节点会通告不正确的链路代价
每个节点只计算自己的路由表
错误信息影响较小,局部,路由较 健壮
因特网中自治系统内部的路由选择
内部网关协议: 自治区内部的协议
外部网关协议: 自治区之间的协议
RIP( Routing Information Protocol )
基于Distance vector 算法实现:
- 距离矢量:每条链路cost=1,# of hops (max = 15 hops) 跳数[ 15最大 ,如果是16 就是不可达 ]
- DV每隔30秒和邻居交换DV,通告
- 每个通告包括:最多25个目标子网
RIP 通告(advertisements)
DV: 在邻居之间每30秒交换通告报文
- 定期,而且在改变路由的时候发送通告报文
- 在对方的请求下可以发送通告报文
每一个通告: 至多AS内部的25个目标网络的 DV
- 目标网络+跳数 【 一次公告最多25个 子网 最大跳数为16 】
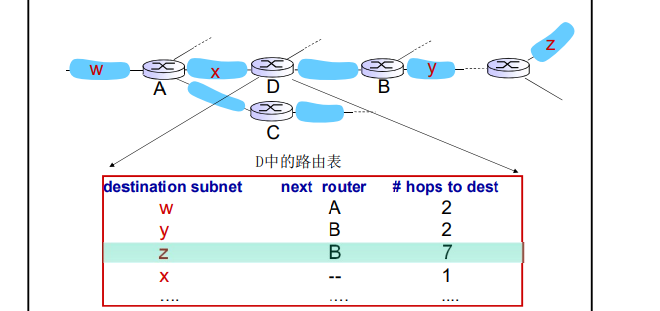
如果180秒没有收到通告信息–>邻居或者链路失效
- 发现经过这个邻居的路由已失效
- 新的通告报文会传递给邻居
- 邻居因此发出新的通告 (如果路由变化的话)
- 链路失效快速(?)地在整网中传输
- 使用毒性逆转(poison reverse)阻止ping-pong回路 (不可达的距离:跳数无限 = 16 段)
RIP 以应用进程的方式实现:route-d (daemon)
通告报文通过UDP报文传送,周期性重复
网络层的协议使用了传输层的服务,以应用层实体的 方式实现
OSPF(Open Shortest Path First)
是基于链路状态(LS)算法实现
- LS 分组在网络中(一个AS内部)分发
- 全局网络拓扑、代价在每一个节点中都保持
- 路由计算采用Dijkstra算法
具体的链路算法怎么算的呢 ?
- 首先链路状态分组会在全网泛洪, 通过这个, 每个节点都会拿到全局拓扑以及代价和 每个节点所能到达目标的汇集树。 从而装载他的路由表
- 按照这个路由表, 对到来的分组进行转发。
IS-IS路由协议:几乎和OSPF一样
OSPF “高级” 特性(在RIP中的没有的)
- 安全: 所有的OSPF报文都是经过认证的 (防止恶意的攻击)
- 允许有多个代价相同的路径存在 (在RIP协议中只有一个)
- 对于每一个链路,对于不同的TOS有多重代价矩阵
- 例如:卫星链路代价对于尽力而为的服务代价设置比较低,对实 时服务代价设置的比较高
- 支持按照不同的代价计算最优路径,如:按照时间和延迟分别计 算最优路径
- 对单播和多播的集成支持:
- Multicast OSPF (MOSPF) 使用相同的拓扑数据库, 就像在OSPF中一样
- 在大型网络中支持层次性OSPF
层次化的OSPF路由
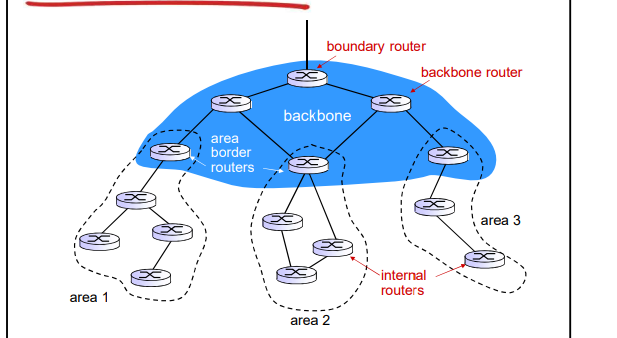
2个级别的层次性: 本地, 骨干
路状态通告仅仅在本地区域Area范围内进行
每一个节点拥有本地区域的拓扑信息;
- 关于其他区域,知道去它的方向,通过区域边界路 由器(最短路径)
区域边界路由器: “汇总(聚集)”到自己区域 内网络的距离, 向其它区域边界路由器通告.
骨干路由器: 仅仅在骨干区域内,运行OSPF路由
边界路由器: 连接其它的AS’s.
ISP之间的路由选择: BGP (自治区域之间的路由选择)
自治区域之间的路由选择。 之前学的(距离矢量算法等等及其一些协议)自治区域内部的协议
层次路由
一个平面的路由
- 一个网络中的所有路 由器的地位一样
- 通过LS, DV,或者其 他路由算法,所有路 由器都要知道其他所 有路由器(子网)如 何走
- 所有路由器在一个平面
平面路由的问题
- 规模巨大的网络中,路由信 息的存储、传输和计算代价巨大
- 管理问题
层次路由:
层次路由: 将互联网 分成一个个AS(路由器 区域)
- 某个区域内的路由器集合,自治系统 “autonomous systems” (AS)
- 一个AS用AS Number (ASN)唯一标示
- 一个ISP可能包括1个 或者多个AS
路由变成了: 2个层次路由
- AS内部路由:在同一个AS 内路由器运行相同的路由协议
“intra-AS” routing protocol:内部网关协议
不同的AS可能运行着不同的 内部网关协议
能够解决规模和管理问题 如:路由选择RIP,OSPF,IGRP
网关路由器:AS边缘路由器 ,可以连接到其他AS
- AS间运行AS间路由协议
“inter-AS” routing protocol:外部网关协议
解决AS之间的路由问题,完 成AS之间的互联互通
层次路由的优点
解决了规模问题
- 内部网关协议解决:AS内部 数量有限的路由器相互到达的 问题, AS内部规模可控
- 如AS节点太多,可分割AS,使 得AS内部的节点数量有限
- AS之间的路由的规模问题
- 增加一个AS,对于AS之间的路 由从总体上来说,只是增加了一 个节点=子网(每个AS可以用一 个点来表示)
- 对于其他AS来说只是增加了一 个表项,就是这个新增的AS如 何走的问题
- 扩展性强:规模增大,性能不会 减得太多
- 解决了管理问题
- 各个AS可以运行不 同的内部网关协议
- 可以使自己网络的细 节不向外透露
互联网AS(自治系统)间路由:BGP
BGP (Border Gateway Protocol): 自治区域间路由 协议“事实上的”标准
“将互联网各个AS粘在一起的胶水”
BGP 提供给每个AS以以下方法:
- eBGP: 从相邻的ASes那里获得子网可达信息
- iBGP: 将获得的子网可达信息传遍到AS内部的所有路由器
- 根据子网可达信息和策略来决定到达子网的“好”路径
- eBGP、iBGP的链接
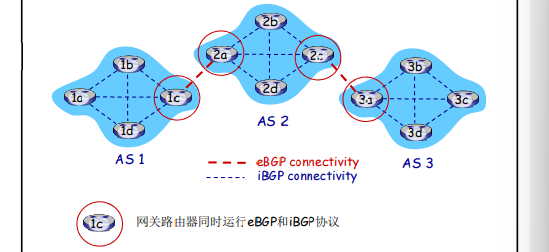
允许子网向互联网其他网络通告“我在这里”
基于距离矢量算法(路径矢量)
- 不仅仅是距离矢量,还包括到达各个目标网络的详细路径(AS 序号的列表)能够避免简单DV算法的路由环路问题
BGP基础:
BGP 会话 : 2个BGP路由器(“peers”)在一个半永久的TCP连接上 交换BGP报文:
- 通告向不同目标子网前缀的“路径”(BGP是一个“路径 矢量”协议)
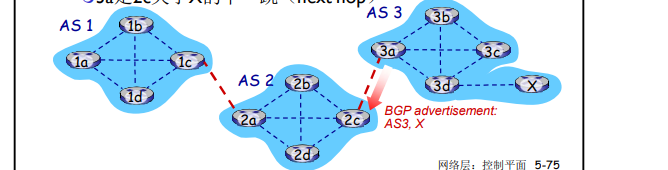
当AS3网关路由器3a向AS2的网关路由器2c通告路径: AS3,X 【3a是2c关于X的下一跳(next hop)】
- 3a参与AS内路由运算,知道本AS所有子网X信息
- 语义上:AS3向AS2承诺,它可以向子网X转发数据报
路径的属性& BGP 路由
当通告一个子网前缀时,通告包括 BGP 属性 [ prefix + attributes = “route” ]
2个重要的属性:
- AS-PATH: 前缀的通告所经过的AS列表: AS 67 AS 17
- 检测环路;多路径选择
- 在向其它AS转发时,需要将自己的AS号加在路径上
- NEXT-HOP: 从当前AS到下一跳AS有多个链路,在NETX-HOP属性中,告诉对方通过那个 I 转发.
- 其它属性:路由偏好指标,如何被插入的属性
基于策略的路由:
- 当一个网关路由器接收到了一个路由通告, 使用输入策略来接受或过滤( accept/decline. )
- 策略也决定了是否向它别的邻居通告收到的这个路由信息
BGP 路径通告
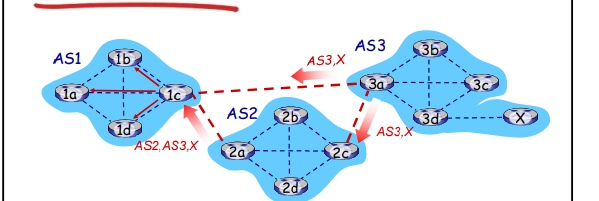
- 路由器AS2.2c从AS3.3a接收到的AS3,X路由通告 (通过 eBGP)
- 基于AS2的输入策略,AS2.2c决定接收AS3,X的通告,而且通过 iBGP)向AS2的所有路由器进行通告
- 基于AS2的策略,AS2路由器2a通过eBGP向AS1.1c路由器通告 AS2,AS3,X 路由信息
- 路径上加上了 AS2自己作为AS序列的一跳
网关路由器可能获取有关一个子网X的多条路径,从多个eBGP 会话上:
- AS1 网关路由器1c从2a学习到路径:AS2,AS3,X
- AS1网关路由器1c从3a处学习到路径AS3,X
- 基于策略,AS1路由器1c选择了路径:AS3,X,而且通过iBGP 告诉所有AS1内部的路由器
BGP报文
使用TCP协议交换BGP报文.
报文包括:
- OPEN: 打开TCP连接,认证发送方
- UPDATE: 通告新路径 (或者撤销原路径)
- KEEPALIVE:在没有更新时保持连接,也用于对 OPEN 请求确认
- NOTIFICATION: 报告以前消息的错误,也用来关闭 连接
BGP 路径选择
路由器可能获得一个网络前缀的多个路径,路由器必须进行路径的选择,路由选择可以基于:
- 本地偏好值属性: 偏好策略决定
- 最短AS-PATH :AS的跳数
- 最近的NEXT-HOP路由器:热土豆路由
- 附加的判据:使用BGP标示
一个前缀对应着多种路径,采用消除规则直到留下一条路径
BGP: 通过路径通告执行策略
为什么内部网关协议和外部网关协议如此不同?
策略:
Inter-AS: 管理员需要控制通信路径,谁在使用它的网络 进行数据传输;
Intra-AS: 一个管理者,所以无需策略;
AS内部的各子网的主机尽可能地利用资源进行快速路由
规模:
AS间路由必须考虑规模问题,以便支持全网的数据转发
AS内部路由规模不是一个大的问题
- 如果AS 太大,可将此AS分成小的AS;规模可控
- AS之间只不过多了一个点而已
- 或者AS内部路由支持层次性,层次性路由节约了表空间, 降低了 更新的数据流量
性能:
Intra-AS: 关注性能
Inter-AS: 策略可能比性能更重要
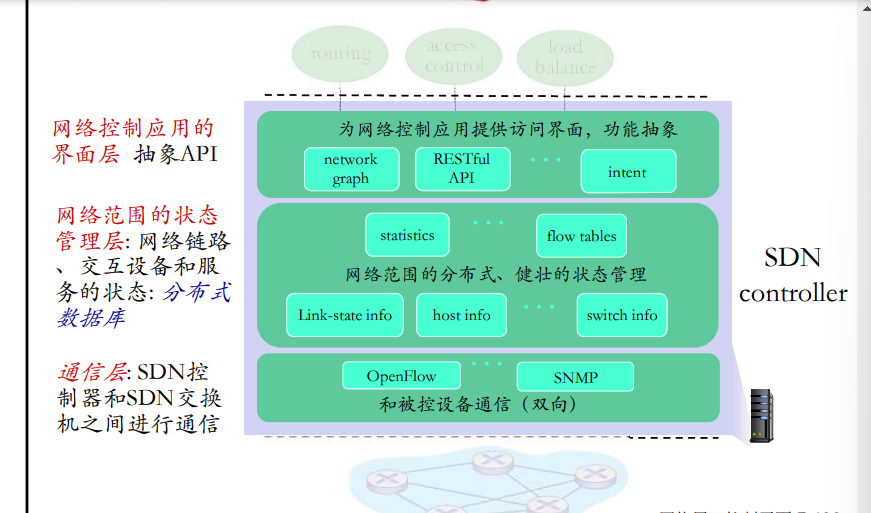
Software defined networking (SDN) 控制器
互联网络网络层:历史上都是通过分布式、每个 路由器的实现
- 单个路由器包含了:交换设备硬件、私有路由器OS( 如:思科IOS)和其上运行的互联网标准协议(IP, RIP, IS-IS, OSPF, BGP)的私有实现
- 需要不同的中间盒来实现不同网络层功能:防火墙, 负载均衡设备和NAT
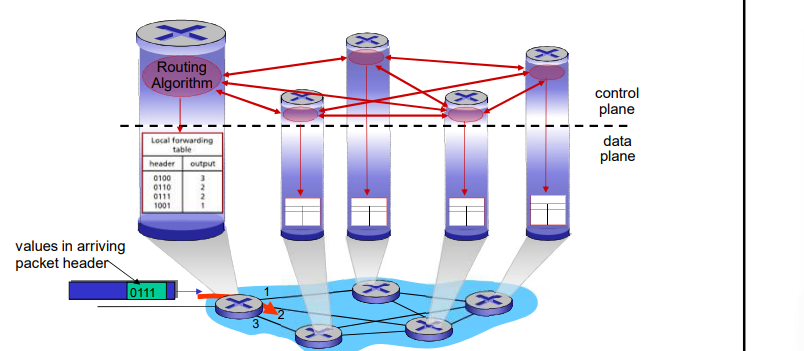
传统的方式: 每-路由器(Per-router)控制平面
在每一个路由器中的单独路由器算法元件,在控制平面进行交互 复杂且难以管理
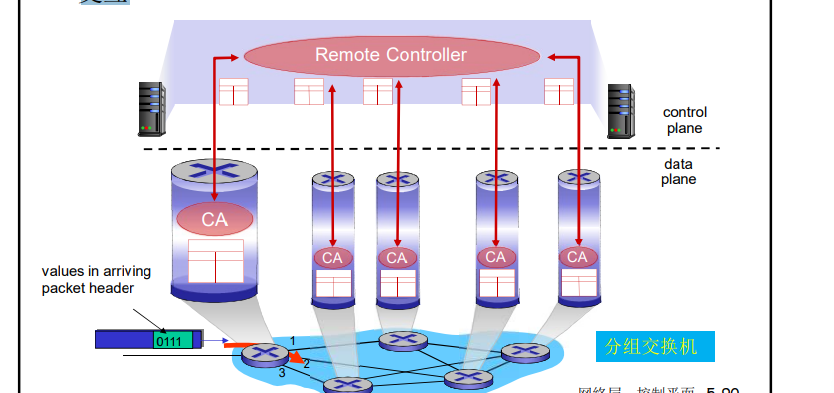
SDN方式: 逻辑上集中的控制平面
一个不同的(通常是远程的)控制器与本地控制代理(CAs) 交互
SDN
SDN的优点:
网络管理更加容易:避免路由器的错误配置,对 于通信流的弹性更好
基于流表的转发(回顾一下OpenFlow API),允 许“可编程”的路由器
- 集中式“编程”更加容易:集中计算流表然后分发
- 传统方式分布式“编程”困难:在每个单独的路由器 上分别运行分布式的算法,得到转发表(部署和升级 代价低) 。而且要求各分布式计算出的转发表都得基本正确
控制平面的开放实现(非私有)
SDN特点:
- 通用“ flowbased” 基于流的 匹配+行动(e.g., OpenFlow)
- 控制平面和数据平面的分离
- 控制平面功能在数据交换设备之外实现
- 可编程控制应用 … 在控制器之上以 网络应用形式实 现各种网络功能
SDN架构
数据平面交换机
- 快速,简单,商业化交换设备 采用硬件实现通用转发功能
- 流表被控制器计算和安装
- 基于南向API(例如OpenFlow ),SDN控制器访问基于流的 交换机
- 定义了哪些可以被控制哪些不能 也定义了和控制器的协议 (e.g., OpenFlow
SDN控制器(网络OS):
- 维护网络状态信息
- 通过上面的北向API和网络 控制应用交互
- 通过下面的南向API和网络 交换机交互
- 逻辑上集中,但是在实现上 通常由于性能、可扩展性、 容错性以及鲁棒性采用分布 式方法实现
网络控制应用
- 控制的大脑: 采用下层提供 的服务(SDN控制器提供的 API),实现网络功能
• 路由器 交换机
• 接入控制 防火墙
• 负载均衡
• 其他功能
- 非绑定:可以被第三方提供 ,与控制器厂商以通常上不 同,与分组交换机厂商也可 以不同
SDN控制器里的元件